우선적으로 appendix, prerequisite 개념으로 쿠버네티스 관련 사전 지식이 필요합니다. 아래 레퍼런스들을 익히고 보는 것이 좋습니다. 익숙하지 않다면 사용 방식에 대해 익히고 넘어가고, 이전 글에서 flask와의 차이 정도만 느끼면 좋을 것 같습니다.
0. Appendix
- Custom Resource(CR) : 쿠버네티스에서 default로 관리하지는 않지만, 배포된 Custom Controller에 의해 쿠버네티스에서 관리되고 있는 리소스들이라고 할 수 있습니다.
https://kubernetes.io/ko/docs/concepts/extend-kubernetes/api-extension/custom-resources/
커스텀 리소스
커스텀 리소스 는 쿠버네티스 API의 익스텐션이다. 이 페이지에서는 쿠버네티스 클러스터에 커스텀 리소스를 추가할 시기와 독립형 서비스를 사용하는 시기에 대해 설명한다. 커스텀 리소스를
kubernetes.io
- Controller : Desired State 와 Current State를 비교하여, Current State 를 Desired State에 일치시키도록 지속적으로 동작하는 무한 루프입니다.
https://kubernetes.io/ko/docs/concepts/architecture/controller/
컨트롤러
로보틱스와 자동화에서 컨트롤 루프 는 시스템 상태를 조절하는 종료되지 않는 루프이다. 컨트롤 루프의 예시: 실내 온도 조절기 사용자는 온도를 설정해서, 사용자가 의도한 상태 를 온도 조절
kubernetes.io
- Operator : Controller pattern 을 사용하여 사용자의 애플리케이션을 자동화하는 것입니다. 주로 CR 의 Current/Desired State를 지속적으로 관찰하고 일치시키도록 동작하는 역할을 위해 사용됩니다.
https://kubernetes.io/ko/docs/concepts/extend-kubernetes/operator/
오퍼레이터(operator) 패턴
오퍼레이터(Operator)는 사용자 정의 리소스를 사용하여 애플리케이션 및 해당 컴포넌트를 관리하는 쿠버네티스의 소프트웨어 익스텐션이다. 오퍼레이터는 쿠버네티스 원칙, 특히 컨트롤 루프를
kubernetes.io
앞으로 다룰 seldon-core, prometheus, grafana, kubeflow, katib를 포함해 쿠버네티스 생태계에서 동작하는 많은 모듈들이 이러한 Operator 로 개발되어 있습니다.
- Helm : ubunto os의 apt, Mac OS의 brew, Python의 pip는 패키지 관리 도구입니다. Helm도 마찬가지로 쿠버네티스 모듈의 Package Managing Tool 입니다. 하나의 쿠버네티스 모듈은 다수의 리소스들을 포함하고 있는 경우가 많습니다. 즉, a.yaml, b.yaml,... 등 많은 수의 쿠버네티스 리소스 파일들을 모두 관리해야 하기 때문에 버전 고나리, 환경별 리소스 파일 관리 등이 어려운데, Helm은 이러한 작업을 템플릿화 시켜 많은 수의 리소스들을 하나의 리소스처럼 관리할 수 있게 도와주는 도구입니다.
1. Seldon Core Install
https://docs.seldon.io/projects/seldon-core/en/latest/workflow/install.html
Install Seldon-Core — seldon-core documentation
First install Helm 3.x. When helm is installed you can deploy the seldon controller to manage your Seldon Deployment graphs. Now we can install Seldon Core in the seldon-system namespace. For full instructions on installation with Istio and Ambassador read
docs.seldon.io
선행되어야할 부분은 다음과 같습니다. 아래 내용을 만족하기 위해 하나씩 실행 및 설치를 하겠습니다.
- 쿠버네티스 환경 (v1.18 이상)
- minikube
- kubectl
- Helm 3
- Ingress Controller
- Ambassador
- Python 환경
- python 3.6 이상
- pip3
1) minikube
minikube start --driver=docker --cpus='4' --memory='4g'2) helm 설치
v3.5.4 설치를 할 예정입니다.
https://github.com/helm/helm/releases
Releases · helm/helm
The Kubernetes Package Manager. Contribute to helm/helm development by creating an account on GitHub.
github.com
위 주소에서 본인 환경에 맞는 주소를 복사해 입력합니다.
# https://github.com/helm/helm/releases 에서 link 확인
wget <URI>
# 압축 풀기
tar -zxvf helm-v3.5.4-linux-amd64.tar.gz
# 바이너리 PATH 로 이동
sudo mv linux-amd64/helm /usr/local/bin/helm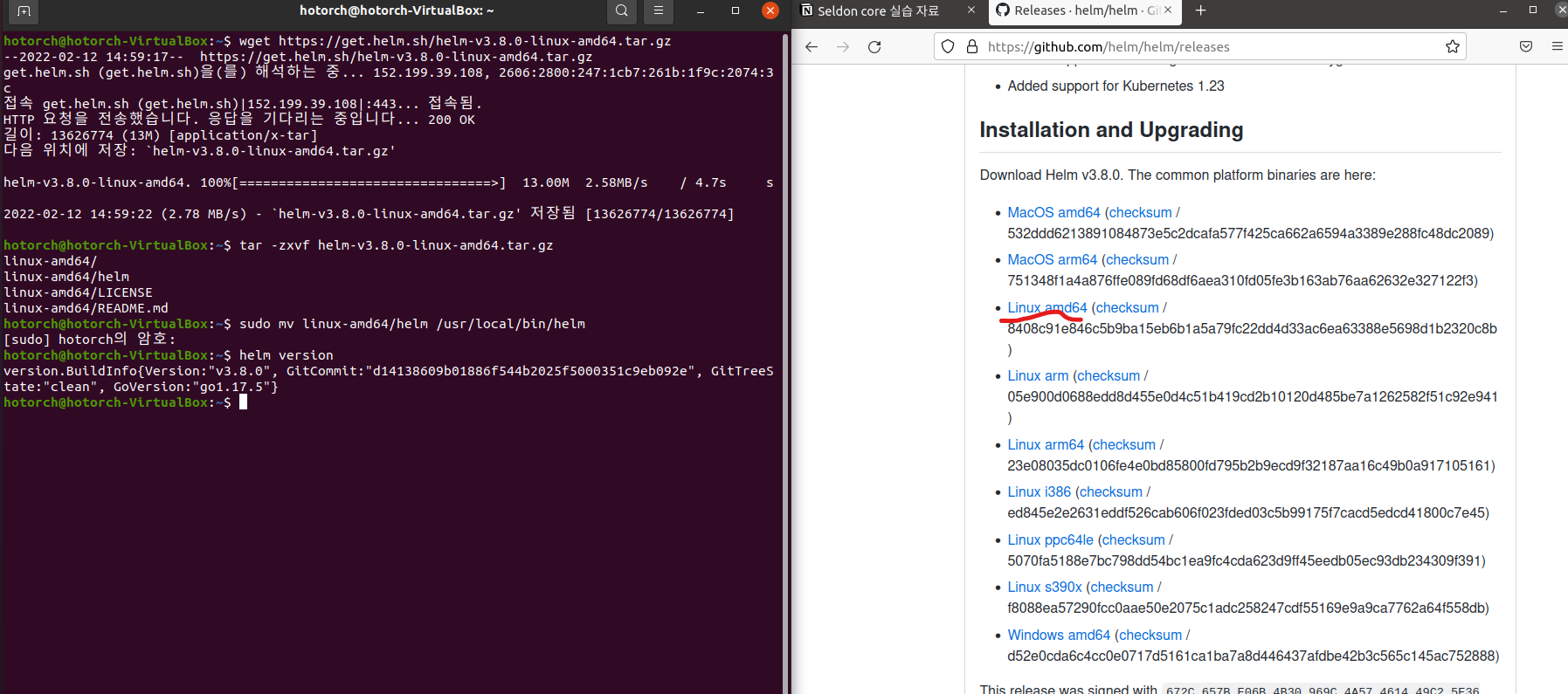
3) ambassador 설치
chart version : ambassador-6.9.1
# ambassador 를 install 하기 위해 public 하게 저장된 helm repository 를 등록
helm repo add datawire https://www.getambassador.io
# helm repo update
helm repo update
# helm install ambassador with some configuration
helm install ambassador datawire/ambassador \
--namespace seldon-system \
--create-namespace \
--set image.repository=quay.io/datawire/ambassador \
--set enableAES=false \
--set crds.keep=false
# 정상 설치 확인
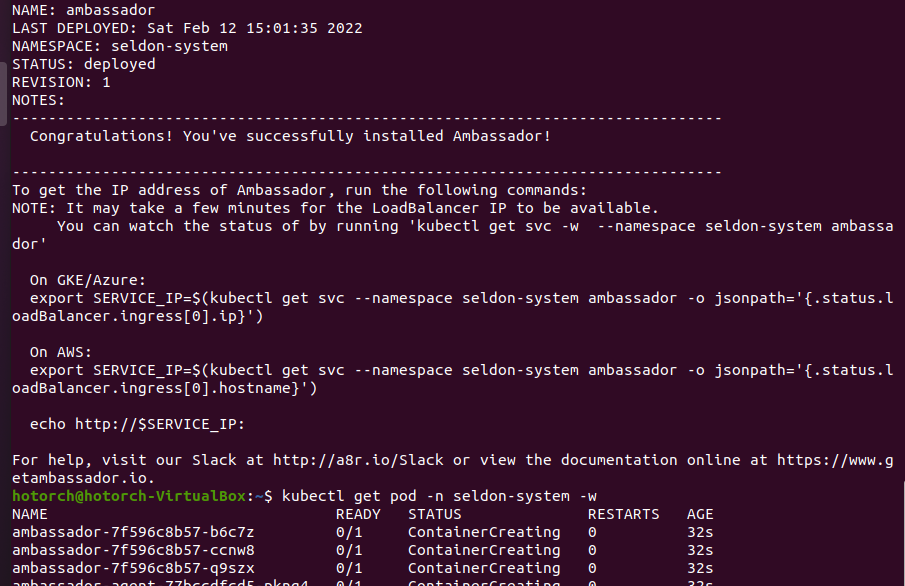
kubectl get pod -n seldon-system -w
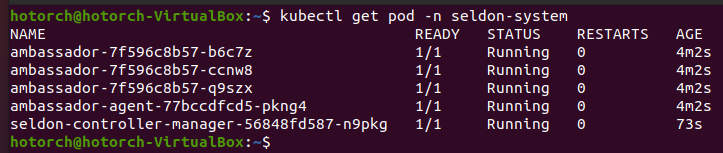
kubectl get pod -n seldon-system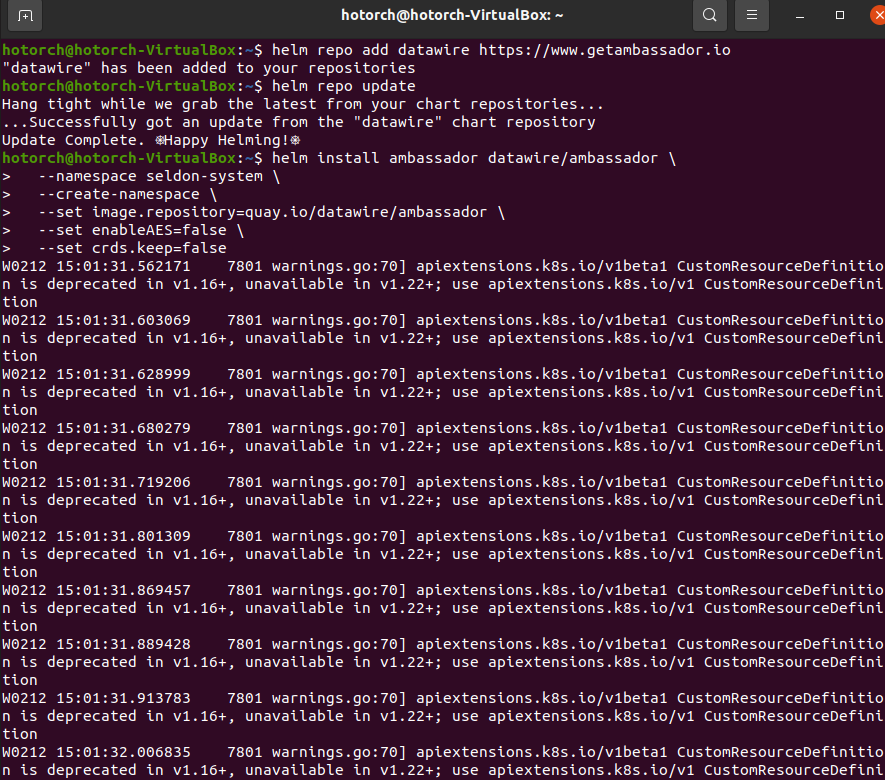
4) Seldon-core 설치
chart version : seldon-core-operator-1.11.0
helm install seldon-core seldon-core-operator \
--repo https://storage.googleapis.com/seldon-charts \
--namespace seldon-system \
--create-namespace \
--set usageMetrics.enabled=true \
--set ambassador.enabled=true
2. SeldonDeployment
Seldon-Core에서 정의한 Custom Resource 중 하나가 SeldonDeployment입니다. 간단하게 말하면 이미 학습이 완료된 model을 로드해서 Serving 하는 Server를 쿠버네티스에서는 SeldonDeployment라고 부르고 관리할 수 있습니다. Flask를 사용하는 경우에 필요했던 작업인 API를 정의하거나, IP, PORT를 정의하거나, API 문서를 작성해야 하는 작업부터, 쿠버네티스에 배포하기 위해 필요했던 docker build, push, pod yaml 작성 후 배포와 같은 작업을 할 필요 없이, trained model 파일이 저장된 경로만 전달하면 자동화된 것이라고 볼 수 있습니다.
이제 Sample Seldon Deployment를 생성해보고, 생성된 SeldonDeployment 서버가 제공하는 URI로 http request를 호출해 정상적으로 응답이 오는지 확인해봅니다. 순차적으로 이를 수행해보겠습니다.
1) Seldon Deployment 생성
Seldon Deployment를 생성할 용도의 namespace를 하나 생성합니다.
kubectl create namespace seldon그 이후 SeldonDeployment YAML 파일(sample.yaml)을 생성합니다. 여기서 graph 아래에 implementation과 modelUri가 핵심이라고 생각하시면 됩니다.
apiVersion: machinelearning.seldon.io/v1
kind: SeldonDeployment
metadata:
name: iris-model
namespace: seldon
spec:
name: iris
predictors:
- graph:
# seldon core 에서 sklearn 용으로 pre-package 된 model server
implementation: SKLEARN_SERVER
# seldon core 에서 제공하는 open source model - iris data 를 classification 하는 모델이 저장된 위치
# : google storage 에 이미 trained model 이 저장되어 있음
modelUri: gs://seldon-models/v1.11.0-dev/sklearn/iris
name: classifier
name: default
replicas: 1 # 로드밸런싱을 위한 replica 개수 (replica 끼리는 자동으로 동일한 uri 공유)
"kubectl apply -f sample.yaml"을 수행합니다.

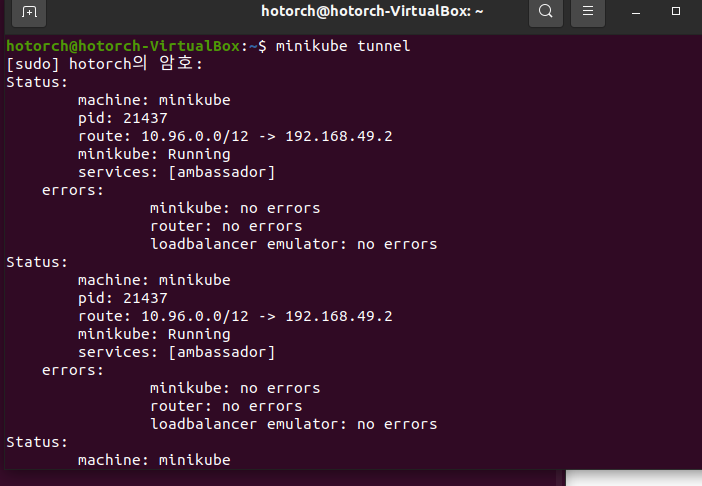
2) minikube tunnel 실행
새 터미널을 열어서 "minikube tunnel"을 수행합니다. 이 터널이 열려있다면, minikube cluster 내부와 통신할 수 있게 됩니다. 이 블로그 글에서의 예제에서는 ambassador와 같은 loadbalancer service를 expose 하여 clusterIP를 externalIP처럼 사용하기 위한 용도로 활용합니다.
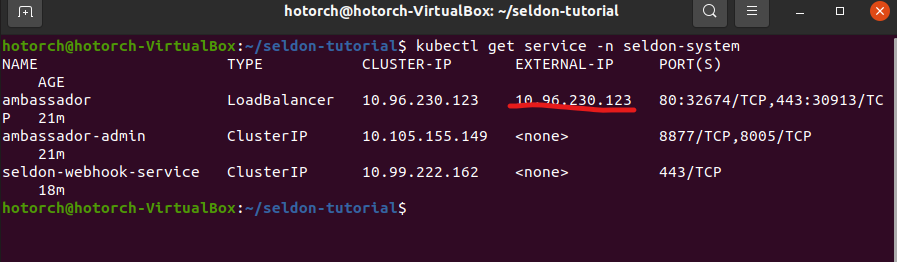
3) ambassador external IP 확인하기
"kubectl get service -n seldon-system"을 실행하여 ambassador의 external ip을 확인합니다.
4) API 문서 확인하기
Seldon Deployment를 생성하면 다음 주소에서 API Reference를 확인할 수 있습니다. "http://<ingress_url>/seldon/<namespace>/<model-name>/api/v1.0/doc/" 형태로 실행을 한번 해봅니다. 아래 그림처럼 나타나면 됩니다. 해당 문서에는 해당 SeldonDeployment에서 지원하는 API와 해당 API의 사용법에 대한 예시가 포함되어 있습니다.

3. API Request 보내보기!
curl을 이용해서 한번 어떻게 나타나는지 확인해보겠습니다. iris 모델이기 때문에 inference 데이터 feature의 수가 4개입니다. 거기에 맞게 한번 보내봅니다.
curl -X POST http://{본인의 ambassador externel IP}/seldon/seldon/iris-model/api/v1.0/predictions \
-H 'Content-Type: application/json' \
-d '{ "data": { "ndarray": [[1,2,3,4]] } }'
일부러 6이라는 값을 더 넣어 일부러 오류를 일으키면 아래와 같은 에러 메시지를 볼 수 있습니다.

파이썬 가상 환경을 활성화하여 위에서 한번 수행해보겠습니다. numpy와 seldon-core가 설치되어있어야 합니다.
pip install numpy seldon-core"test.py"를 아래 코드를 복사해 넣습니다. IP 부분에 Externel-IP를 삽입합니다.
import numpy as np
from seldon_core.seldon_client import SeldonClient
sc = SeldonClient(
gateway="ambassador",
transport="rest",
gateway_endpoint="{IP Insert}", # Make sure you use the port above
namespace="seldon",
)
client_prediction = sc.predict(
data=np.array([[1, 2, 3, 4]]),
deployment_name="iris-model",
names=["text"],
payload_type="ndarray",
)
print(client_prediction)
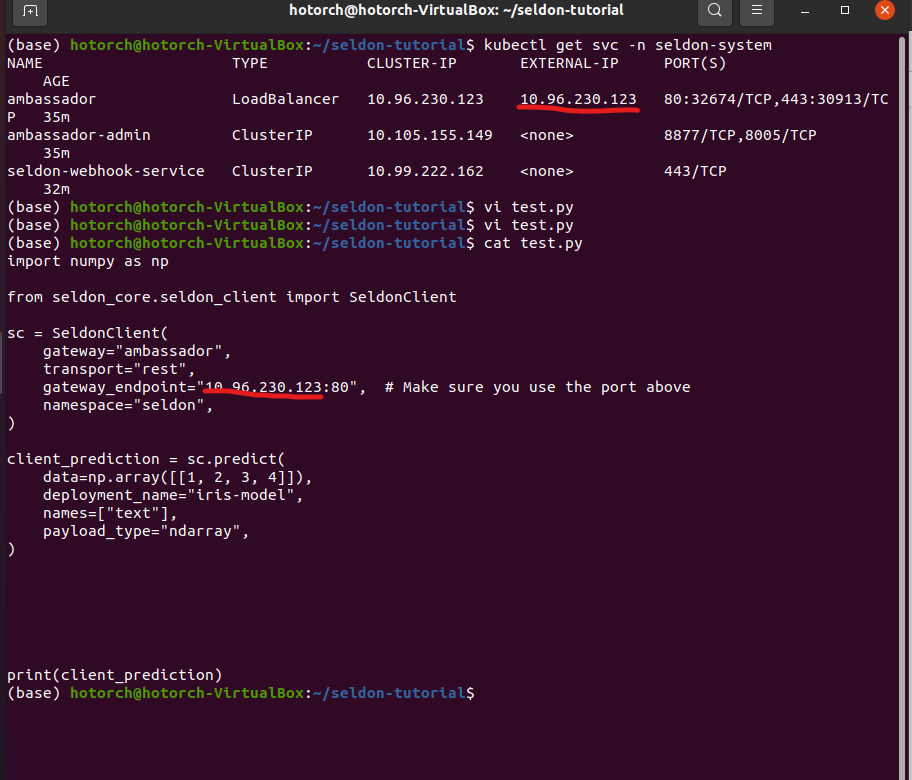
그다음 test.py를 수행해봅니다. 이전 curl로 수행했을 때 같은 결과를 얻을 수 있는 것을 알 수 있습니다.

이렇게 간단한 예제 이외에도 SeldonDeployment는 여러 모델 앙상블 결과 하나의 인퍼런스 서버 앙상블도 가능하고 해 볼 수 있는 것이 많다고 합니다. 구글 스토리지에 모델 파일을 넣어서도 돌릴 수 있고, mlflow와 같은 곳에서 저장된 모델을 불러서 활용이 가능합니다. 또한 Model Management 툴 mlflow 과의 연동성이 뛰어나다고 하네요.
쿠버네티스 사전적으로 알아야 하는 용어와 개념이 많아 조금 어려운 파트로 느껴집니다. 다음 글에서는 모니터링 관련 글로 찾아뵙겠습니다!
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
* 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
 |
 |

'AI > MLOps' 카테고리의 다른 글
| [패스트캠퍼스 챌린지 22일차] Prometheus & Grafana 개념 (0) | 2022.02.14 |
|---|---|
| [패스트캠퍼스 챌린지 21일차] Model Monitoring 개념 (0) | 2022.02.13 |
| [패스트캠퍼스 챌린지 19일차] Flask (0) | 2022.02.11 |
| [패스트캠퍼스 챌린지 18일차] Model Serving 개념 (0) | 2022.02.10 |
| [패스트캠퍼스 챌린지 17일차] MLflow 튜토리얼 (2) (0) | 2022.02.09 |
