
AI 분야를 공부하거나 업계에서 종사한다면, 항상 문제 되는 이슈는 데이터 셋입니다. 요리를 만들어서 내놓으라고 하지만, 요리사 입장에서는 재료부터 없다면 머리가 뜨끈해지기 때문입니다. 이번 글은 제가 알고 있는 오픈된 자연어처리(Natural Language Processing) 한국어 데이터만을 다루고자 합니다. 현업에서도 어떤 모델이나 실험 설계 시, 간단하게 테스트를 해보거나 벤치마크 용으로 많이 활용하는 것이 오픈된 데이터입니다. 그럼 시작해 보겠습니다.
Hugging Face
첫번째로는 허깅페이스(Hugging Face) 입니다. Transformers 라이브러리와 User가 Pre-trained 모델 및 데이터셋을 공유할 수 있는 자연어처리 플랫폼으로 가장 유명합니다. 우측 상단 데이터셋 탭에서 한국어를 따로 filter 검색하여 확인이 가능합니다.

모두의 말뭉치
두번째로는 모두의 말뭉치 입니다. 사용 방법은 아래 모두의 말뭉치 유튜브 채널에 친절하게 설명하고 있습니다.

신청하고 데이터를 수령받는데 약 3 영업일 소요됩니다. 승인이 되면 아래와 같은 진행 상황으로 바뀝니다.

처음에 마음대로 신청하였다가, 반려를 당한 적도 있으니 유튜브 채널에 신청 방법 보고 따라서 해보는 것을 권장합니다.

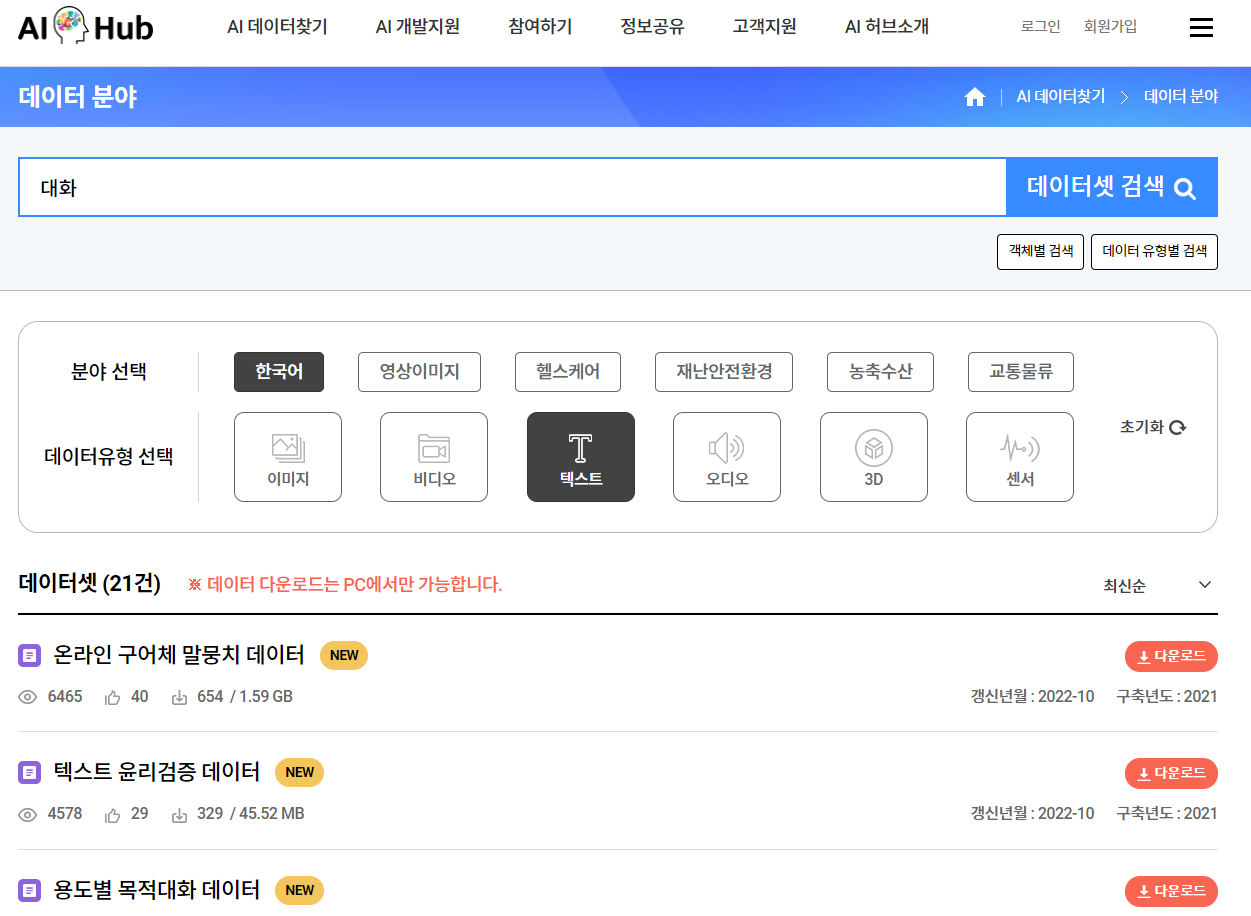
AI Hub
세번쨰로는 AI Hub 입니다. 가입하고 쉽게 다운로드하여 활용할 수 있습니다. 아래 그림과 같이 목적에 맞는 데이터 검색하여 찾아서도 볼 수 있습니다.
Kaggle
네번째로는 예측 모델 및 분석 대회 플랫폼으로 많이 알려진 Kaggle(캐글)입니다. 경진대회 code 및 노트북, Discussion 뿐만 아니라 5~6년 전부터 캐글 쪽에서도 데이터 셋을 공유할 수 있게 되었습니다. 아래 사진은 'korean'이라고 검색했을 때 결과입니다.

Dacon
다섯번째로는 국내 관련 인공지능 경진대회 플랫폼인 Dacon(데이콘) 입니다. 대회와 목적에 맞는 Task가 내가 하고자 하는 실험 설계가 일치하는 경우 해당 대회의 데이터를 받아 활용하는 편입니다. 단점으로는 스폰서나 주최 측의 요청으로 데이터를 받지 못하는 경우도 참고하여야 합니다.

Github
마지막으로는 Github 입니다. 깃헙에는 많은 사람들 코드도 공유하지만 small 데이터들도 공유하긴 합니다. 아래는 Markdown에 한국어 데이터를 모은 Repository입니다. 참고하시면 좋을 것 같습니다.
https://github.com/ko-nlp/Korpora
GitHub - ko-nlp/Korpora: Korean corpus repository
Korean corpus repository. Contribute to ko-nlp/Korpora development by creating an account on GitHub.
github.com
https://github.com/songys/AwesomeKorean_Data
GitHub - songys/AwesomeKorean_Data: 한국어 데이터 세트 링크
한국어 데이터 세트 링크. Contribute to songys/AwesomeKorean_Data development by creating an account on GitHub.
github.com
이 글을 마치며
위에 소개한 글들에서 본인이 실험하고 싶은 Task에 맞지 않거나 도메인에 맞는 데이터가 없는 경우에는 어쩔 수 없이 눈물을 머금고 각종 작업을 수행할 수 있습니다. 예를 들어, 가지고 있는 데이터에 라벨을 부여해 주는 annotation tool들을 활용하는 방법이 있고, 특정 모델을 들고 오거나 API Key(opanai api 등)를 발급받아 생성하는 방법이 있습니다. 아니면 가지고 있는 데이터를 바탕으로 여러 augmentation 기법들을 적용하여야 합니다.
제가 알고 있는 한국어 데이터를 모은 곳들은 여기까지 입니다. 이번 글에서 소개한 부분 외에 데이터가 없다면, 저도 고뇌에 빠져들곤 합니다. 이 글이 자연어처리를 업으로 하거나 연구하는 많은 분들이 각자의 자리에서 좋은 연구 결과물이나 모델을 만드시면 좋겠습니다. 소개한 부분 이외에 독자분들이 알고 있는 한국어 데이터 셋이 있다면 댓글 달아주시면 감사하겠습니다.
아래는 블로그 주인장의 토스 익명 후원 링크입니다. 글이 너무 너무 도움되거나 흡족스러웠다면 후원해주시면 감사하겠습니다.
hotorch님에게 보내주세요
토스아이디로 안전하게 익명 송금하세요.
toss.me

'AI > NLP' 카테고리의 다른 글
| ChatGPT를 활용한 Application Framework - LangChain (0) | 2023.04.05 |
|---|---|
| ChatGPT 사용법 A-Z, 예시, 한계점 및 시사점 (3) | 2022.12.22 |
| Dependency Parsing (1) (0) | 2022.04.17 |
| 오프라인(인터넷이 안되는)환경에서 Pre-trained Language Model 모델 부르기 with PORORO (0) | 2022.04.02 |
| Pretrained Language Model - 14. BART (0) | 2021.11.11 |
