
이전 글에서는 Vector DB가 떠오르고 있는 배경과 왜 필요한지에 대해 글을 작성하였습니다.
2023.06.10 - [AI/Vector Database] - [Vector DB] 1. Vector Database 배경 & 필요성
[Vector DB] 1. Vector Database 배경 & 필요성
올해 상반기 AI sector에서 핫한 토픽은 AI를 보다 일반인들에게 쉽게, 친숙하게 접근할 수 있는 ChatGPT였습니다. 여기서 같이 수혜주로 받은 것은 Vector Database 분야입니다. 이미 Faiss, Redis, ScaNN 기존
hotorch.tistory.com
이번 글에서는 Vector DB 종류들을 (아주) 간단하게 알아보겠습니다.
Vector Database 종류
먼저 한 번에 알아보기 쉽게 한 테이블로 정리해 보면 다음과 같습니다. 제시된 Vector Database들의 강점은 자체적인 알고리즘으로 색인과 유사한 벡터들을 검색을 해준다는 것입니다. (최대한 글을 쓴 시점 기준 최대한 정보를 반영했지만 틀린 부분도 있을 수 있습니다.) 또한 일부 VectorDB는 GPU를 바탕으로 retrieval을 해주는 경우도 존재합니다. (단, GPU는 Data 건수마다 제한 조건이 존재하며 상이함)
| Vector DB 이름 | Company | Cloud 가능 유무 | 오픈소스 유무 (지원 언어) |
사용 알고리즘 | 개인적인 의견 |
| Weaviate | SeMI | O | O (Python, Go, Java, JS) |
Custom HNSW | 쿼리를 유연하게 가져가고 싶다면 고려할 수 있는 VectorDB |
| Milvus | Ziliz | X | O (Python, Go, C++) |
ANN, HNSW, ANNOY | 규모가 큰 경우 상당히 좋다고 알려져있음. document도 깔끔한 편 |
| Vespa | Yahoo! | O | O (Java, C++) | HNSW (graph) | 기능이 풍부하다고 알려져있고 검증이 충분히 되어있음 |
| Vald | Yahoo! | X | O (Go) | NGT | |
| Chroma | Chroma | O | O (Python, JS) | HNSW | faiss 와 마찬가지로 설치가 편함(local에 구성) AI 쪽에 특화(Chroma 에서 주장하고 있음) |
| Qdrant | Qdrant | N | O (Rust) | HNSW (graph) | |
| Pinecone | Pinecone | O | X | 복합으로 사용하며, 독점 상태 | 자료가 상당히 많은 편이고, 빠르게 Prototype으로 실험, 시작, 검증하기 좋음. |
| GSI APU for ES(Elasticsearch)/ Opensearch |
GSI | X | X | Neural hashing / Hamming distance | - |
사용되는 여러 알고리즘이 다 비슷비슷하면서도 다양합니다. 참고로 ANN(근접/이웃) 관련 알고리즘은 Pinecone에서 제시한 아래 링크에서 자세히 읽어보시면 좋겠습니다. 품질과 검색속도, 메모리 부분들도 비교한 내용이 있습니다.

https://www.pinecone.io/learn/vector-indexes/
Nearest Neighbor Indexes for Similarity Search | Pinecone
An overview and comparison of similarity search indexes.
www.pinecone.io
더 다양한 Vector Database 내용은 아래 표를 참고해주세요. (Vector DB Feature Matrix)
https://docs.google.com/spreadsheets/d/170HErOyOkLDjQfy3TJ6a3XXXM1rHvw_779Sit-KT7uc/edit#gid=0
개인적인 생각 & 한계점
좋은 tool들이 나오면 한번 이것저것 써보고 싶은 것이 사람 마음입니다. 인덱싱을 개선도 해주는데, DB 역할까지 해주니 군침이 흐를 수 있습니다. 하지만 제대로 활용하려면 본격적으로 도입하기 전에 니즈나 활용방안을 깊게 고민하면서 본인 상황에 맞게 사용하는 것입니다. 또한 정말로 본인이 Vector Database가 필요한지 물어봐야 합니다.
즉, 본인이 핸들링하거나 관리하는 데이터의 수나 실시간 또는 배치성으로 얼마나 데이터들이 유입되는지 등을 판단해보아야 합니다. 또한 위의 표에서는 클라우드나 오픈소스 유무로만 언급했습니다. 일단 전체적으로 이 Vector Database 기술을 사용하는 게 좋은지 어떤지 입장별로 나누어서 제 생각을 작성해 보겠습니다.
1. 보수적인 입장인 경우
올해 상반기에 Vector Database 가 Hype을 받은 것은 langchain이나 llamaindex와 같은 LLM을 위한 보조 도구 때문입니다. 원래 과거에는 이미지/문서 검색 그리고 추천 시스템 쪽이 원래 목적이었다고 합니다. 실제로 검색 속도는 상당히 빠른 것이 큰 강점이지만, insert를 하는 데이터들의 수가 실시간 또는 하루에 매우 많은 경우에 대해서는 고민을 해봐야 합니다. 단점을 간단하게 나열하면 다음과 같습니다.
- embedding 하려는 dimension 크기가 높은 경우, ANN 알고리즘들이 품질 저해
- Vector Database가 차지하는 메모리가 큰 편에 속하기에 Prerequisites를 점검할 필요가 있음
- 실제로 임베딩을 해서 indexing 하는 데에도 시간이 오래 걸리는 이슈 존재. 계산 복잡도가 높고, Cost가 엄청남
- Vector Database는 빠른 계산을 위해서 similarity를 미리 계산하지만, 이 부분은 모든 데이터들에 대한 similarity를 계산해야 한다는 의미
- batch로 처리할지, realtime으로 처리할지에 따라 입장을 고려해보아야 함
- 실제로 collection을 구성하고 데이터들을 밀어 넣는데, 시간이 Vector Database 마다 차이가 있겠지만 확실히 소요가 되는 편
Vector Database의 단점이나 한계점에 대한 포스팅 글은 다음과 같습니다. 제목만 보면 궁금해지는 글들로 구성하였습니다.
- "Do you actually need a vector database?" : 벡터 데이터베이스가 실제로 필요한지에 대한 포스팅
- "Understanding the Fundamental Limitations of Vector-Based Retrieval for Building LLM-Powered Chatbots" : LLM과 Vector 기반으로 검색하는 것과 한계에 대한 내용을 다룬 글입니다. 미국의 20여 명으로 구성된 스타트업의 대표가 3편으로 나누어 쓴 글입니다. 내용은 참 길고, 본인 회사 홍보성 내용이 있지만 내용들과 그림 좋아서 공유합니다.
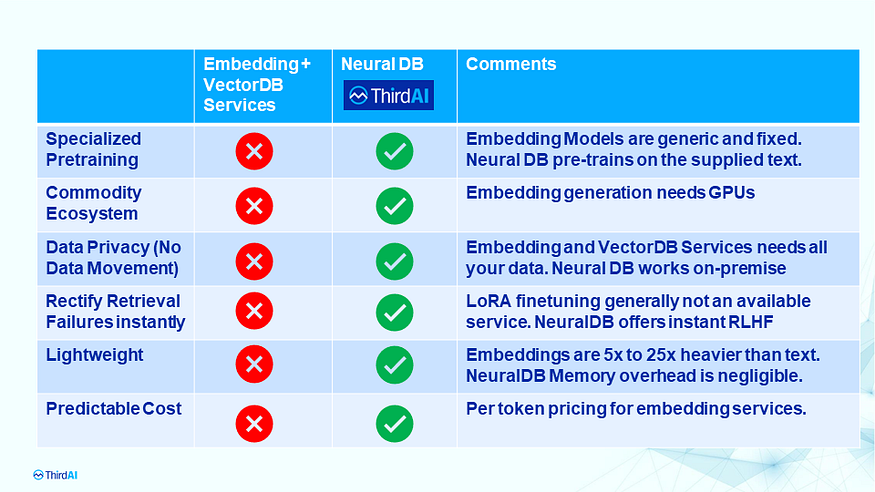
2. 찍어 먹어보고 싶은 경우 - DB가 없는 경우
독자분들의 러닝 커브도 괜찮다고 판단이 되고, 이 기술을 적용하기에 충분한 데이터를 가지고 있다는 마음을 먹었다면 어디서부터 시작을 해보아야 하나?라는 의문이 생깁니다. 먼저 ANN(Approximate Nearest Neighbor) Index Tool들을 활용해 보는 것인데, 이를 나열해 보면 다음과 같습니다.
- 대표적인 건 FAISS 입니다. CPU, GPU 모두 지원하고 다양한 ANN 알고리즘을 지원해 줍니다.
- 나머지 Hnswlib, nmbslib, Annoy 등이 있습니다. 이 3개는 각자 미는 장단점이 다르고, 아래 그림도 한번 참고해 보시면 좋겠습니다.
- 여기서 프로덕션 단계에서 제일 그나마 합리적인 선택은 FAISS + HNSW 이 조합으로 접근하는 것을 추천합니다.

하지만 이 VectorDB를 쓰려는 이유와 본질은 index가 아니라 Information Retrieval 시스템이 핵심입니다. ANN 또한 마찬가지로 한계가 있고 검색으로 얻고자 하는 것이 명확한지 점검하는 것이 좋을 것 같습니다.
3. 찍어 먹어보고 싶은 경우 - 아래 DB가 만약에 존재한다면?
우선 하고 있는 일이 정말로 Embedding 이 적재되어야 하는 DB가 필요한지? 아니면 그냥 DB가 필요한 지를 물어봐야 합니다. 이미 DB에 ANN, NN을 지원해 주는 DB가 있으며 알고리즘을 지원해 준다고 합니다. 대표적으로 postgres의 pgvector 가 존재합니다.
이 글을 마치며 & Reference
다음 글부터 Vector Database들 중 milvus 관련된 내용들을 하나씩 다루고자 합니다. 많고 많은 vectorDB들 중에서 milvus를 선정한 이유는 오로지 단순하게, Documents가 처음 봤던 것보다 많이 발전하였고 오픈소스이면서 star 수가 가장 높아서 선정(작성일 기준 21.5K)하였습니다. 실제로 조금밖에 써보진 않았지만 속도도 흡족하였습니다.
1. Vector Database 개념 글
https://discuss.pytorch.kr/t/gn-vector-database/
[GN] Vector Database가 무엇인가요?
GeekNews의 xguru 님께 허락을 받고 GN에 올라온 글들 중에 AI 관련된 소식들을 공유하고 있습니다. 😺 소개 AI 어플리케이션들은 Vector Embeddings에 의존 임베딩은 AI 모델에 의해 생성되며, 많은 수의
discuss.pytorch.kr
2. Dmitry Kan 선생님은 검색만 16~7년 경력의 ai scientist입니다. vector podcast 쪽 분야 유튜브 또한 운영하고 있습니다.
3. 상위 Vector DB 7개 간단 소개
https://press.ai/best-vector-databases/
Best Vector Databases 2023: Top 7+ Solutions Providers
In this detailed guide, we look at the best Vector databases that are popular in 2023 and help you to choose the most suitable one for your needs.
press.ai
Milvus 관련 글
2023.10.10 - [AI/Vector Database] - [Vector DB] 3. Milvus 튜토리얼 (1) - 설치, 변수 정의, Collection 생성하기
2023.10.12 - [AI/Vector Database] - [Vector DB] 4. Milvus 튜토리얼 (2) - Collection에 데이터 insert 하기
2023.10.13 - [AI/Vector Database] - [Vector DB] 5. Milvus 튜토리얼 (3) - Query 임베딩 생성 & Vector DB 검색하기
2023.10.19 - [AI/Vector Database] - [Vector DB] 6. Milvus 튜토리얼 (4) - Collection에 데이터 Upsert 하기
아래는 블로그 주인장의 토스 익명 후원 링크입니다. 글이 도움되거나 흡족스러웠다면 후원해주시면 감사하겠습니다.
hotorch님에게 보내주세요
토스아이디로 안전하게 익명 송금하세요.
toss.me
'AI > Vector Database' 카테고리의 다른 글
| [Vector DB] 6. Milvus 튜토리얼 (4) - Collection에 데이터 Upsert 하기 (4) | 2023.10.19 |
|---|---|
| [Vector DB] 5. Milvus 튜토리얼 (3) - Query 임베딩 생성 & Vector DB 검색하기 (2) | 2023.10.13 |
| [Vector DB] 4. Milvus 튜토리얼 (2) - Collection에 데이터 insert 하기 (0) | 2023.10.12 |
| [Vector DB] 3. Milvus 튜토리얼 (1) - 설치, 변수 정의, Collection 생성하기 (4) | 2023.10.10 |
| [Vector DB] 1. Vector Database 배경 & 필요성 (2) | 2023.06.10 |
