PLM계열의 Auto-Encoder 계열, 가장 많이 쓰이고 활용되고 있는 BERT 차례입니다. 이전에 글 쓴 GPT 계열은 단방향(Uni-directional) 언어 모델이기 때문에, 문장 앞까지만 보고 추측하는 것이기 때문에 문장 전체에 대한 이해가 부족합니다. 마치 한국어는 끝까지 들어봐야 한다라는 말이 있듯이 BERT 계열은 Bi-directional 언어 모델이기 때문에 Fine-Tuning 단계에서 꽤 많은 성능을 올릴 수 있습니다.
0. BERT와 이전 모델의 차이점
- BERT : Performance가 검증된 트랜스포머 블록을 사용 + 모델의 속성이 양방향을 지향하는 점에 있습니다.

- GPT는 왼쪽에서 오른쪽으로 한 방향(uni-direction)으로만 보는 아키텍처(언어모델) 입니다.
- ELMo는 Bi-LSTM 레이어의 상단은 Bi-direction입니다. 하지만 중간 layer는 Uni-direction, concatenate만 실시합니다. 이 부분이 bi-directional 한 느낌이 부족하다고 설명합니다.(shallow Bi-directional)
- BERT는 Unsupervised pre-training → transfer learning, supervised data, ELMo는 Feature Based(Bert도 근데 Feature Based로 접근해도 성능이 잘 나온다고 합니다. )
1. BERT의 구조와 Objective
- Transformer의 Encoder만을 활용하는 것이 특징입니다.
- MLM과 NSP 두 가지 Task를 수행하면서 Pre-train을 실시합니다.
- Word Embedding과 순서 사상을 반영한 Positional Embedding을 넣는 것뿐만 아니라 Sentence Embedding을 추가하여 여러 Embedding을 합하여 Input으로 활용합니다.
2. Pre-train Task - MLM(Masked Language Model)

- MLM(Masked Language Model)이 제일 중요한 역할이자 핵심입니다. 일정 비율의 단어에 구멍을 뚫어서 이를 맞추도록 하는 Task입니다.
- 다음 time-step의 단어를 예측하는 기존 LM과 다르게, MLM은 현재 time-step의 토큰을 예측하는 것입니다. 이를 통해 Auto-regressive 한 성격을 탈피한 Bi-directional LM을 만들 수 있습니다.
- 각 단어 위치의 값들은 문장 전체의 정보를 활용할 수 있습니다.
- Denoising Auto Encoder랑 느낌은 비슷하나, masking 된 단어만 예측합니다. masking된 단어만을 복원한다고 생각하시면 됩니다.
- 학습과 추론의 괴리를 없애기 위한 MLM의 실험 설계는 다음과 같습니다.
① corpus의 15%의 토큰만 추론해야 할 대상으로 선정합니다.
② 방금 15%의 80%를 MASK를 시켜 빈칸을 뚫습니다. (전체의 12%) 이 부분은 문장 내 어느 자리에 어떤 단어를 쓰는 게 자연스러운지 앞뒤 문맥 읽기가 가능한 기대효과를 지닌다고 할 수 있습니다.
③ 또한 10%를 랜덤 토큰으로 변환시킵니다. (전체의 1.5%) 이 부분은 주어진 문장이 의미/문법적으로 비문인지 아닌지 판단하기 때문입니다.
④ 남은 10%를 그대로 내버려둡니다. (전체의 1.5%)
이러한 Pre-train 데이터를 위와 같이 만들고 수행하는데, 헷갈리면 헷갈릴수록 더 고도의 언어 모델이 된다고 생각하시면 됩니다. 모델은 어떤 단어가 masking 될지 모르기 때문에 문장 내 모든 단어 사이의 의미와 문법적 관계를 살피기 때문이죠.
3. Pre-train Task - NSP(Next Sentence Prediction)
다소 MLM보다는 중요도가 떨어지는 Task이지만 살펴보겠습니다.

- 앞뒤 문장의 관계를 살피기 위한 목적입니다. corpus에서 임의로 두 문서를 연결을 시킵니다.
- 이후에, 앞 문서 뒤에 연결되는 뒤 문서에 대해서 50% 확률로 임의로 대체합니다.
- 또한 문서 사이에 <SEP> 토큰을 삽입하고, 문장의 시작에는 항상 <CLS> 토큰을 넣습니다. <CLS> 토큰 위치에서 NSP 대체 여부 예측하도록 학습시킵니다.
- 이어진문장이 맞는지 아닌지, 반복 학습하여 문장 간 의미 관계를 이해합니다. 일부 문장 성분이 없어도 전체 의미를 이해하는데 큰 무리가 없습니다. 그 이유는 NSP Task가 너무 쉬워지는 것을 방지하기 위해서 문장 맨 앞 또는 맨 뒤 단어를 삭제하는 Pre-train 학습 데이터 구성 단계에서 작업을 하긴 합니다.
- NSP 부분에 대해서 학습 데이터 구성하는 부분을 생략을 하겠습니다. 크게 중요하다고 생각하지 않으며, 추후에 이 부분에 대해서 다른 PLM들은 NSP를 시도하지 않기 때문입니다.
4. Embedding I/O

기존 Transformer은 단어 임베딩과 Positional Encoding을 합해서 들어갑니다. 하지만 BERT는 문장 임베딩과 Positional 임베딩까지 합하여 들어갑니다. 여기서 토큰의 종류는 아래와 같이 정리할 수 있습니다.
- [CLS] : 문장의 시작
- [SEP] : 문장 구분, 문장 종결
- [MASK] : 빈칸
- [PAD] : 배치 데이터 길이를 맞춰주기 위함
5. Fine Tuning
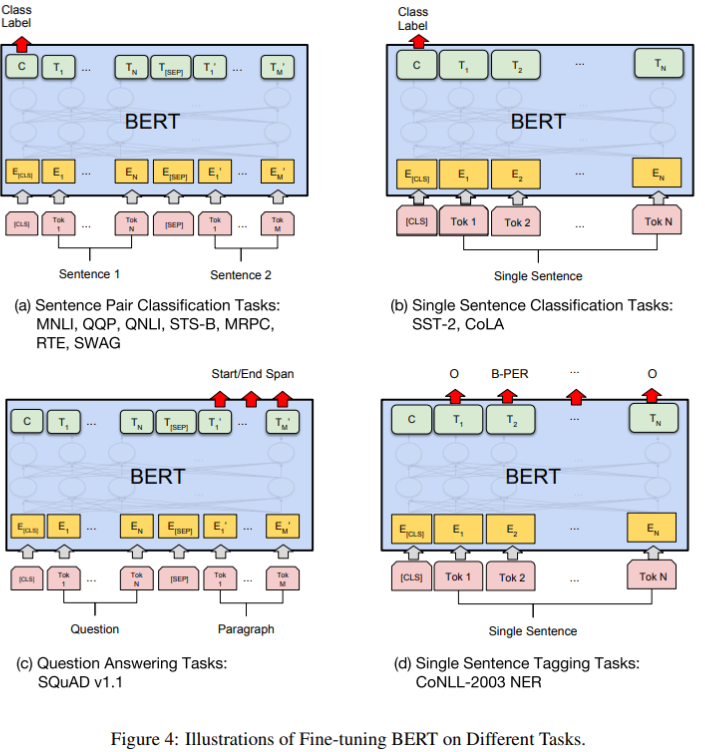
BI-Directional LM이기 때문에 NLU Task에만 적용이 가능하며 NLG(챗봇, 번역기)에는 적용할 수 없습니다.
- Text CLS : <CLS> 토큰 위치에 Softmax layer 추가하여 Fine Tuning을 실시합니다.

- Spanning : QA나 MRC 등에서 사용하기 위해 Weight vector S와 E 추가합니다. 시작과 끝을 알려주는 idx를 알려주는 것이 spanning입니다.
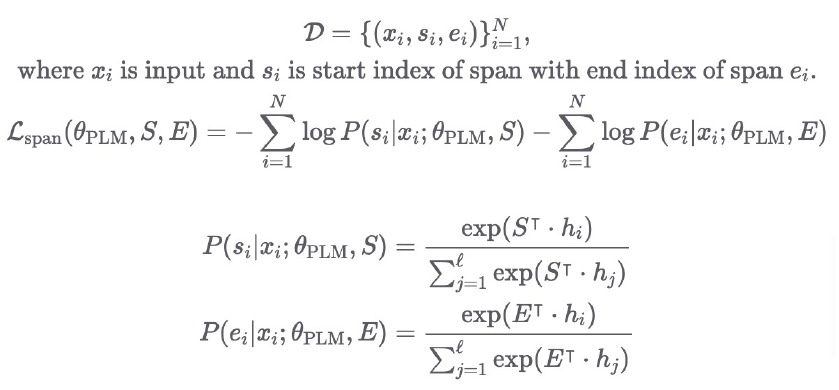
밑에 2개의 조건부 확률에서 S, E는 hidden size의 벡터이며, 이 수식은 Softmax 이기 때문에 시작과 끝의 확률 분포를 구합니다.
6. Evaluation
그냥 이때 당시에는 가장 잘 나왔다고 생각하시면 됩니다.
7. 정리하면
- MLM이라는 혁신적인 방법을 통해 기존 LM 방식에 벗어난 Bi-LM을 탄생시킴으로써 NLU Task에서 SOTA 성능을 뽑았습니다.
- Huggingface(Godggingface라고 많이 부르는)와 같은 라이브러리를 통해 누구나 쉽게 양질의 Text Classifier를 얻을 수 있습니다.
- NLG Task에서 transfer learning을 수행할 수 없습니다.
- 기존 방식에 비해 큰 모델을 사용하였으며, 모델의 크기가 커짐에 따라 성능이 더더욱 개선이 되었고, 가장 대중적인 PLM 모델이 되었습니다.
<Reference>
아래 BERT가 NLP에서 게임 체인저가 되었는지, 조금 다소 긴 영상이지만 좋은 웨비나 링크 남기고 가겠습니다.
https://peltarion.com/webinars/nlp-and-bert
How NLP and BERT will change the language game | Peltarion
Learn how natural language processing (NLP) powered by deep learning is about to change the game for many organizations interested in AI, thanks to BERT.
peltarion.com
2년 전에 스터디했을 때 자료들을 일부 들고 왔습니다. 지금 보니 상당히 옛날 자료이긴 하지만 좋은 내용들이어서 레퍼런스로 남깁니다.
한국어 임베딩 - YES24
자연어 처리 모델의 성능을 높이는 핵심 비결, 『한국어 임베딩』임베딩(embedding)은 자연어를 숫자의 나열인 벡터로 바꾼 결과 혹은 그 일련의 과정 전체를 가리키는 용어다. 단어나 문장 각각을
www.yes24.com
BERT 톺아보기 · The Missing Papers
BERT 톺아보기 17 Dec 2018 어느날 SQuAD 리더보드에 낯선 모델이 등장했다. BERT라는 이름의 모델은 싱글 모델로도 지금껏 state-of-the-art 였던 앙상블 모델을 가볍게 누르며 1위를 차지했다. 마치 ELMo를
docs.likejazz.com
BERT 논문정리 · MinhoPark
Batch size: 16, 32 Learning rage (Adam): 5e-5, 3e-5, 2e-5 Number of epochs : 3, 4
mino-park7.github.io
BERT : Pre-training of Deep Bidirectional Transformers Language Understanding
BERT : Pre-training of Deep Bidirectional Transformers Language Understanding
Abstract
www.notion.so
GitHub - dhlee347/pytorchic-bert: Pytorch Implementation of Google BERT
Pytorch Implementation of Google BERT. Contribute to dhlee347/pytorchic-bert development by creating an account on GitHub.
github.com
'AI > NLP' 카테고리의 다른 글
| Pretrained Language Model - 14. BART (0) | 2021.11.11 |
|---|---|
| Pretrained Language Model - 13. RoBERTa (0) | 2021.11.05 |
| Pretrained Language Model - 11. GPT (0) | 2021.10.31 |
| Pretrained Language Model - 10. Tokenization (0) | 2021.10.31 |
| Pretrained Language Model - 9. Language Model (0) | 2021.10.24 |
