feature store에 대한 개념과 필요성을 중점적으로 서술합니다. AS-IS > To-Be로 이어지는 느낌의 글이라고 생각하면 됩니다.
1. 구성 모습 & 정의
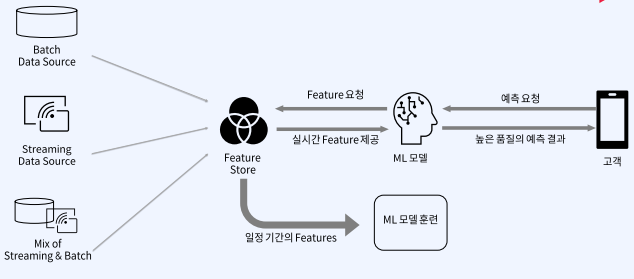
Feature Store는 활용 모습에 따라 다양한 구성 요소를 가질 수 있습니다. 실시간성 스트리밍 데이터나 특정 주기마다 데이터를 모아서 한번에 적재를 한 배치 데이터를 Input으로 받아, 모니터링, 데이터 변형, 레지스트리 등의 역할을 하는 것이 Feature Store입니다.
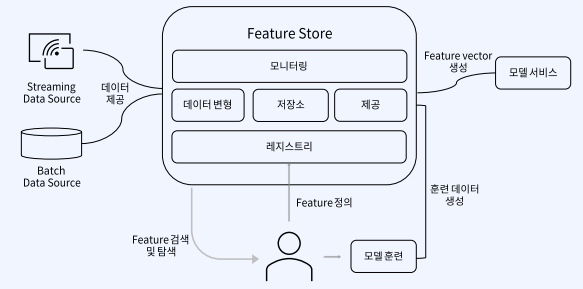
과거에는 스크립트를 기준으로 백엔드에서 수행하거나 Feature pipeline을 만들고 공유하고 같은일을 반복 수행하였지만 이제 Data Scientist들은 이를 바탕으로 Feature에 대해 검색, 탐색, 정의, 벡터 생성등을 수행합니다. 이처럼 Feature Store은 모델 훈련과 배포 과정의 중복을 줄이기 위해 생겨난 관리형 플랫폼이라고 생각하시면 됩니다.
2. Feature 추출과 제공의 어려움
현실은 실시간 데이터와 배치성 데이터 혼합된 경우가 많습니다. 정말 아래 그림처럼 쉽게 예측한 내용을 주고 받을 수 있을까요? 이에 대한 어려운 점들을 짚어 보겠습니다.
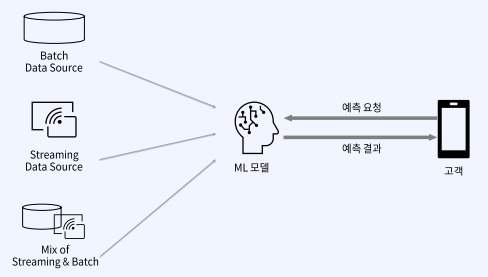
1) 데이터의 양과 빈도 뿐만 아니라 RawData의 종류에 따라 지원되는 데이터 transform을 하는데에 전부 다른 문제가 존재합니다. Snowflake같은 경우에는 변형이 자유롭지만 데이터의 양과 빈도가 주고받는 타임프레임이 짧아질 수록 변형하기 어려워 집니다. 아래 그림을 참고하시면 되겠습니다.

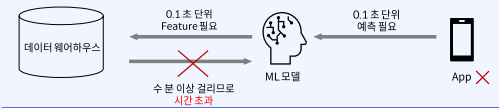
2) App이 필요한 시간 안에 Feature를 제공하지 못합니다.
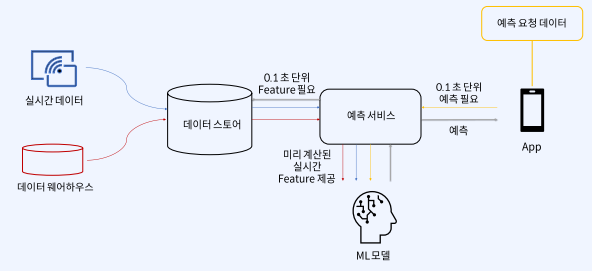
따라서 아래처럼 개선을 하고자 한다면, 아래와 비슷합니다. 미리미리 적재하여 Feature들을 계산하고 소비하는 형태입니다.

하지만 현실은 ETL로 1일에 한번씩 미리 계산하여 적재하는 옛날 방식이 아닌, 비용과 빈도를 최적화 시켜 ETL로 미리 계산을 해야하는 것이 정말 원하는 모습일 것 입니다.

3) Batch 데이터와, Real Time 데이터, 예측 요청 데이터를 한 번에 처리하는 것이 상당히 어렵습니다. 아래 그림과 같이 다른 색깔의 선들을 참고하시면 됩니다.
4) 데이터 누수에 의해 훈련/제공 데이터의 차이가 발생할 수 있습니다. 예측 시점에 알고 있는 데이터와 예측 시점에 모르는 데이터 사이에 괴리가 발생하기 때문에 해당 모델이 실제로 실시간으로 데이터를 받았을 때와 학습과 평가했을 때의 괴리와 오류를 잡지 못하는 위험이 생깁니다.
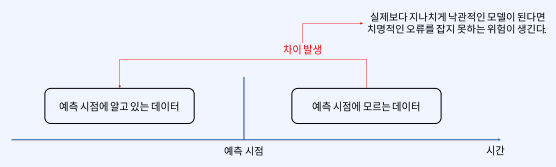
따라서 위의 문제를 해결하기 위해 탄생한 것이 feature store이고, 미리 피처 파이프라인을 정의해놓고 짧은 주기에 대해서도 높은 품질의 피처를 제공하는 것이 큰 특징입니다.
3. 현실 : Data Pipeline에 익숙하지 않은 ML Team 구성인 경우
이 부분은 제 경험담이기도 해서 많이 느꼈던 부분이였습니다. 아래 그림과 같은 현상이 반복되면 엔지니어는 일의 우선순위가 밀리고, 복잡한 Feature Pipeline을 구성하게 되며 인프라와 운영에 집중을 못합니다.

DataScientist 입장에서도 모델 최적화 시간에 할애 못하고, 좋은 모델을 못 만든다는 뜻입니다. 양쪽 모두 피처 관리하는데 부담감이 심해진다는 뜻입니다.

따라서 해결책은 피처 스토어를 활용하여 Feature Pipeline만 잘 정의해두면 자동적으로 데이터 엔지니어들도 인프라와 운영에도 더 집중해서 긍정적인 결과를 이끌 수 있는 이점이 있습니다.
4. 데이터 관리 어려움 - 표준화
아래와 같이 다양한 모델에 대해 각각 원천 데이터를 이용해 모델 생성을 하게되면, 여러 분석 시스템에서 데이터를 중복 사용하여 관리가 어렵게 됩니다. 즉, 비전, 추천, 디텍팅 등 다양한 모델을 활용한다고 한다면, 리소스 낭비가 심하고 관리가 어렵습니다.

Feature Store를 쓰면 아래와 같이 Feature들을 데이터 자산의 하나로 관리가 가능해집니다.
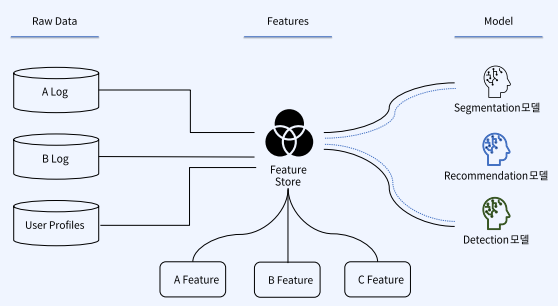
5. 데이터 문제 발생 시 운영중인 모델 중지
데이터에 이슈가 생기면 운영에 배포된 모델 서비스가 중지되어야합니다. 일반적인 SW와 다르게 AI Project는 "데이터"가 존재하기 때문입니다. 데이터에 이슈가 생기면 Raw Data의 Feeding을 멈추어 연결이 끊기게 된다거나, 데이터 품질 신뢰도가 떨어진다거나, 실행이 가능한 Feature들의 분포가 급격히 바뀌게 됩니다. 이를 Feature Store를 이용해 데이터 품질 신뢰도를 얻고, 일정한 분포를 지닌 Feature를 활용하여 모델에 적용을 합니다.
다음 글에는 Feast 관련 글로 찾아 뵙겠습니다.
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
* 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
 |
 |

'AI > MLOps' 카테고리의 다른 글
| [패스트캠퍼스 챌린지 33일차] Feast - Store 생성 & 배포 (0) | 2022.02.25 |
|---|---|
| [패스트캠퍼스 챌린지 32일차] Feast 소개 (0) | 2022.02.24 |
| [패스트캠퍼스 챌린지 30일차] Feature Engineering & ML Pipeline (0) | 2022.02.22 |
| [패스트캠퍼스 챌린지 29일차] Kubeflow Katib Practice (0) | 2022.02.21 |
| [패스트캠퍼스 챌린지 28일차] Kubeflow Katib (0) | 2022.02.20 |
