1. Katib Experiment - random search
Katib Experiment 리소스 yaml 예제를 보면서 각 필드가 어떤 의미를 가지는지 이해를 해보겠습니다.
" random-example.yaml " 로 작성하였습니다.
spec 윗부분은 meta 정보인데, 이전 글에서부터 쭈욱 사용하였던 experiment에서 name은 demo, namespace는 kubeflow-user-example-com입니다. 중요한 부분은 spec 부분부터 입니다. 필드별로 하나씩 보면서 주석을 중점적으로 살펴보시면 됩니다.
apiVersion: "kubeflow.org/v1beta1"
kind: Experiment
metadata:
namespace: kubeflow-user-example-com # namespace
name: demo # experiment name
# Experiment 관련 메타 정보 작성
spec:
# Objective Function
# 최적화하기 위한 metric, type, early stopping goal 등을 포함
objective:
type: maximize
goal: 0.99
# Trial 에서 출력할 때, 정해진 형식으로 StdOut 으로 출력하면 name 을 parsing 할 수 있음
# https://www.kubeflow.org/docs/components/katib/experiment/#metrics-collector
# objectiveMetricName 은 hp search 를 수행할 objective metric 의 이름
# addtionalMetricName 은 hp search 와는 관계없지만 함께 출력할 metric 의 이름
objectiveMetricName: Validation-accuracy
additionalMetricNames:
- Train-accuracy
# Hyperparameter Search Algorithm
algorithm:
# Katib 에서는 현재 지원하고 있는 search algorithm 이 다음과 같이 정해져 있음. 아래 참고
# https://www.kubeflow.org/docs/components/katib/experiment/#search-algorithms
# 각각의 algorithm 은 정해진 HP search package 를 사용하여 동작하며,
# 어떤 docker image 를 사용할 것인지는 katib 설치 당시 배포한 configmap 에 적혀있음
# 다음 명령을 통해서 어떤 algorithm 이 어떤 package 를 사용하는지 확인할 수 있음
# 각 algorithm name에 따라 다른 패키지를 사용함
# `kubectl get configmap katib-config -o yaml` 을 실행후 아래 쪽에 suggestion 필드 확인
algorithmName: random
## 일단 실험을 많이 하고 싶다면 개수를 늘리면 되는데, 일단 테스트 용으로 1개씩만 할당함
# 1. 병렬로 실행할 Trial 의 개수
parallelTrialCount: 2
# 2. 최대 Trial 개수 (도달하면 실험 종료 : Succeeded status 로 종료)
maxTrialCount: 2
# 3. 최대 failed Trial 개수 (도달하면 실험 종료 : Failed status 로 종료)
maxFailedTrialCount: 2
# HP Search 를 수행할 space 정의
# 각각의 hyperparameter 마다 type 은 무엇인지, space 는 무엇인지를 정의
# https://github.com/kubeflow/katib/blob/195db292374dcf3b39b55dcb3fcd14b3a55d5942/pkg/apis/controller/experiments/v1beta1/experiment_types.go#L186-L207
parameters:
- name: lr # 뒤의 필드 중 trialTemplate.trialParameters[x].reference 와 일치해야함. (중요, 실수하기 쉬운 부분)
parameterType: double
feasibleSpace:
min: "0.01"
max: "0.03"
- name: num-layers
parameterType: int
feasibleSpace:
min: "2"
max: "5"
- name: optimizer
parameterType: categorical
feasibleSpace:
list:
- sgd
- adam
- ftrl
# Suggestion 에 의해 생성된 HP 후보 조합 하나를 input 으로 받아서 학습 및 평가를 진행할 Trial 의 템플릿
trialTemplate:
# 아래 trialSpec.spec.template.spec.containers[x].name 중에서 metric 을 출력하는 container 의 이름
# 지금 예시에서는 container 가 하나뿐이므로 해당 container 의 이름으로 출력
primaryContainerName: training-container
# 아래 trialSpec.spec.template.spec.containers[x].command (or args) 에서 사용할 Hyperparameter 에 대한 메타 정보 정의
# trialParameters[x].name 은 아래 trialSpec 에서의 값과 매핑되며,
# trialParameters[x].reference 는 위의 parameters[x].name 과 매핑됨(위와 반드시 일치시키기)
trialParameters:
- name: learningRate
description: Learning rate for the training model
reference: lr
- name: numberLayers
description: Number of training model layers
reference: num-layers
- name: optimizer
description: Training model optimizer (sdg, adam or ftrl)
reference: optimizer
# Workerjob에 해당하는 부분
# trialSpec 으로는 Job, TfJob 등의 리소스를 사용할 수 있으며, 본 예시는 Job 을 사용함
# https://www.kubeflow.org/docs/components/katib/trial-template/
trialSpec:
apiVersion: batch/v1
kind: Job
spec:
template:
# 현재 버전의 katib 는 istio sidecar 와 함께 사용할 수 없음
# 자세한 내용은 다음 페이지를 확인하세요
# https://www.kubeflow.org/docs/components/katib/hyperparameter/#example-using-random-search-algorithm
# https://github.com/kubeflow/katib/issues/1638
# annotation에서 istio 관련 에러가 꽤 많이 존재한다고 함. 위 이슈를 참고하시면 되고,
# 이번 글에서는 중요한 부분은 아님
metadata:
annotations:
sidecar.istio.io/inject: 'false'
spec:
containers:
- name: training-container
# 해당 이미지는 미리 docker build and push 되어있어야 사용 가능
# 해당 docker image 를 빌드한 Dockerfile 및 소스코드는 다음 경로에서 확인
# https://github.com/kubeflow/katib/tree/983a867/examples/v1beta1/trial-images/mxnet-mnist
# 아래 도커 이미지를 가져다 쓸 예정임
image: docker.io/kubeflowkatib/mxnet-mnist:v1beta1-45c5727
# 아래 argparse들 참고하여 활용할 예정임
command:
- "python3"
- "/opt/mxnet-mnist/mnist.py"
- "--batch-size=64"
- "--lr=${trialParameters.learningRate}"
- "--num-layers=${trialParameters.numberLayers}"
- "--optimizer=${trialParameters.optimizer}"
- "--num-epochs=1" # 테스트 시 시간 소요를 줄이기 위해 epoch 은 1 회만 수행!
restartPolicy: Never
2. Quick Start
- current namespace 를 user namespace로 변경합니다.
- kubens kubeflow-user-example-com
- random-example.yaml(위에 작성한 코드 복사 하여 해당 경로에 yaml 파일이 있다고 가정)을 kubectl로 생성해봅니다.
- kubectl apply -f random-example.yaml

- 리소스별 진행 상황을 확인합니다. (experiment, suggestion, trial, pod)
- watch -n1 'kubectl get experiment, suggestion, trial, pod'
- 1초마다 진행되는 것을 볼 수 있고, 다 되면 사라집니다.
- watch -n1 'kubectl get experiment, suggestion, trial, pod'

- kubectl logs <pod-name> -c metrics-logger-and-collector
- pod 이름을 복사해서 (pod/demo-~~~~) 실행하면 실험한 해당 로그를 볼 수 있습니다.

이렇게 yaml 파일을 실행시켜 수행하는 방법이 있습니다. 이제 UI 위에서 확인을 해보겠습니다.
- UI에서도 확인해봅니다.
- 포트 포워딩
- k port-forward svc/istio-ingressgateway -n istio-system 8080:80
- UI 접속 후 Experiments(AutoML) 탭 접속
- localhost:8080
- 포트 포워딩

위의 yaml파일에서 trail 2로 설정한 만큼 실험이 수행된 것을 알 수 있습니다.
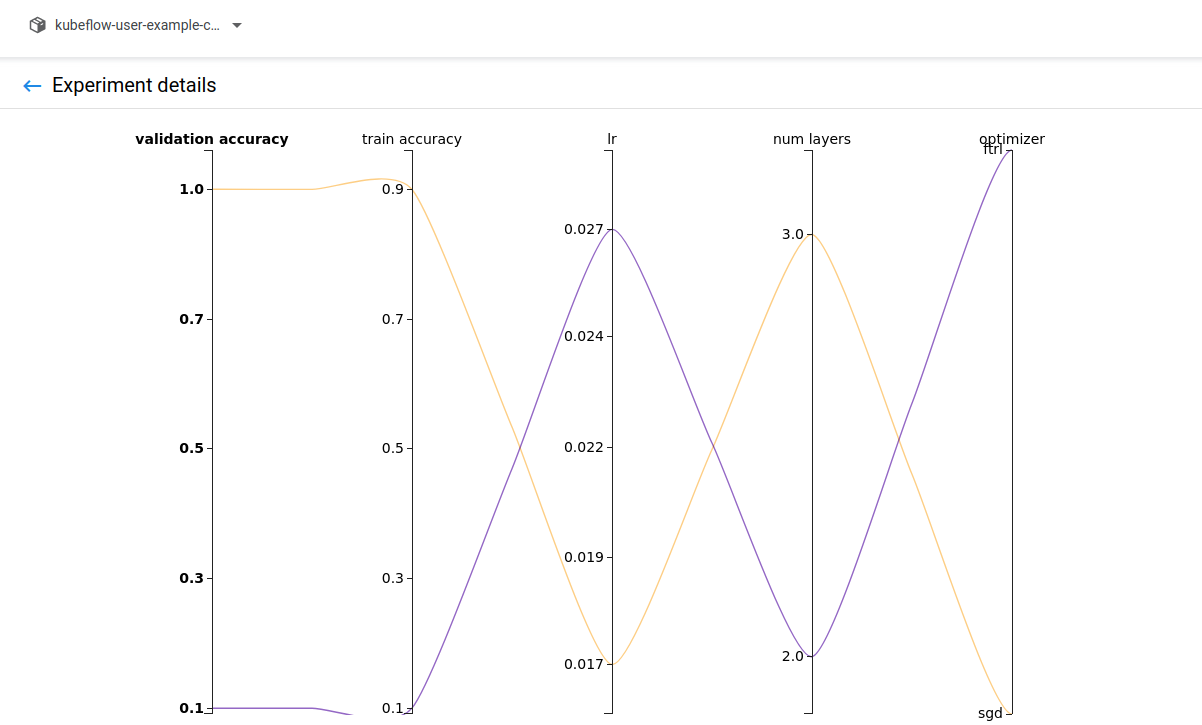

실은 UI 위에서도 설정이 가능합니다.
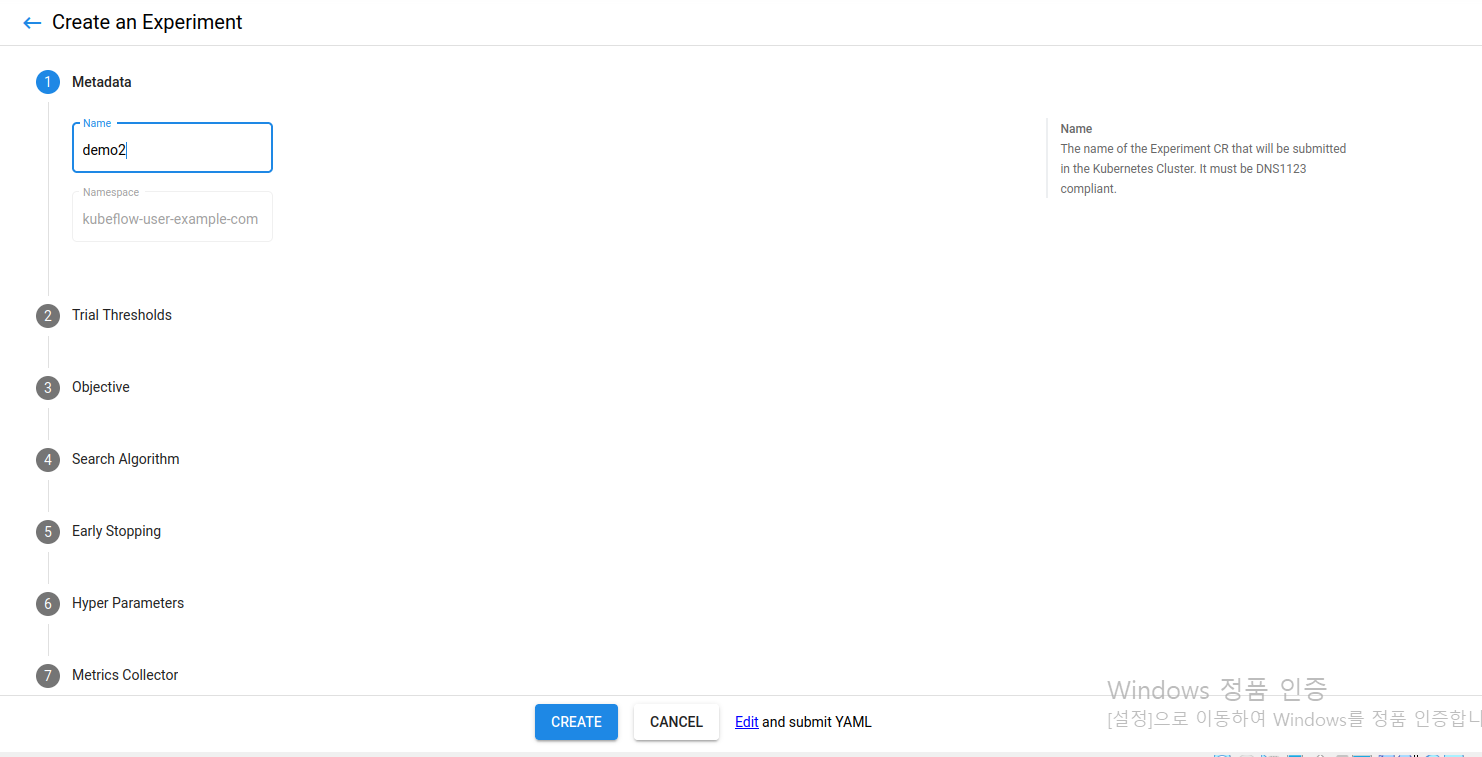
experiment(automl) 탭을 들어가서 우측 상단에 +New Experiment를 누르면 아래와 같이 나타납니다. Name은 - 과 같은 기호가 들어가선 안된다고 합니다.
실험하고 싶은 횟수를 기입합니다.

따로 training accuracy 등과 같은 metric은 따로 넣어도 되고 넣지 않고 싶다면 휴지통 버튼을 누릅니다.

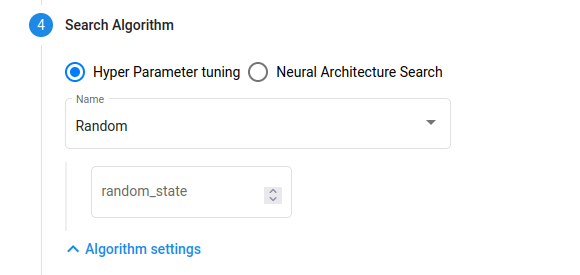
따로 random_state를 부여하여 실험도 가능합니다. hp를 튜닝하는 다양한 방법도 선택이 가능합니다.
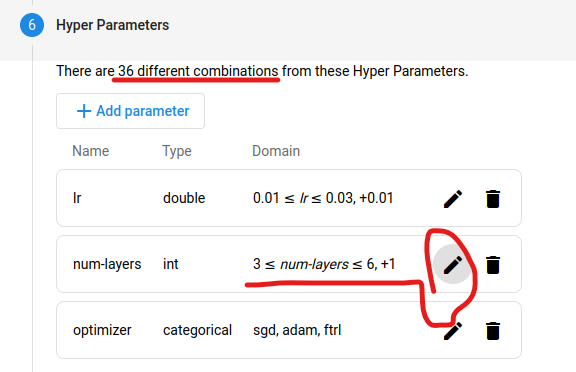
layer 수를 줄이니 combinations 수가 줄어드는 것을 확인하였습니다. 실험하고 싶은 수와 시간을 적절히 생각하며 search space를 조정합니다.
yaml 파일 마지막 부분이 아래쪽에 그대로 반영되어있음을 알 수 있습니다.

아래쪽에 reference를 맞춰주면 됩니다. 그다음 create를 누르고 실험하는 시간을 기다리면 더 살펴볼 수 있습니다.


automl을 yaml 파일을 kubectl로 생성하여 살펴보았습니다. 다음 글에서는 feature에 관한 내용을 중점적으로 다루어볼 예정입니다.
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
* 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
 |
 |

'AI > MLOps' 카테고리의 다른 글
| [패스트캠퍼스 챌린지 31일차] Feature Store (0) | 2022.02.23 |
|---|---|
| [패스트캠퍼스 챌린지 30일차] Feature Engineering & ML Pipeline (0) | 2022.02.22 |
| [패스트캠퍼스 챌린지 28일차] Kubeflow Katib (0) | 2022.02.20 |
| [패스트캠퍼스 챌린지 27일차] Kubeflow Pipeline (2) (0) | 2022.02.19 |
| [패스트캠퍼스 챌린지 26일차] Kubeflow Pipeline (1) (0) | 2022.02.18 |
