Natural Language Generation은 auto-regressive task로 접근합니다. 즉, Language Model은 주어진 단어들을 바탕으로 다음 단어를 예측하는 형태이고 가장 기본이 되는 것이 Sequence to Sequence(seq2seq) 입니다.

Sequence to Sequence는 3개의 서브 모듈 Encoder, Decoder, Generator로 구성이 되어있습니다. Encoder는 문장 하나를 context vector로 압축하는 역할, Decoder는 context vector를 conditional 하게 받는 조건부 LM입니다. Generator는 Decoder의 매 Time step별 hidden state를 softmax를 통해 multinoulli distribution으로 변환합니다.

위의 그림은 문장 길이에 따른 BLEU Score입니다. 기존에는 Seq-to-Seq에서 LSTM 셀을 이용한 Seq2 Seq는 성능이 상당히 안 좋았습니다. 특히 긴 문장에서는 대처가 되질 않습니다. 하지만 여기에 Attention까지 더했을 때 긴 문장에 대해서도 성능이 어느 정도 향상이 되었음을 알 수 있습니다.
2016년에 구글에서 LSTM을 기반으로 한 기계번역모델(GNMT)이 나오고, Facebook에서 2017년 초에 Fully Convolutional Seq2Seq이 나와서 좋은 성능을 보였습니다. 하지만 구글에서 다시 엄청난 논문이 나왔습니다. 그것이 Attention is all you need 라는 논문이며, NLP 공부하는 사람들이 다 한 번씩 읽어본 논문이라고 생각합니다. 그래서 이번 시간에는 Attention에 대해서 다루어보도록 하겠습니다.
직관적으로 살펴보면 이 Attention은 좋은 정보를 잘 얻기 위한 Query를 만드는 한 과정이라고 생각하면 됩니다. Decoder의 나의 상황에서 Encoder에 넘겨받은 필요한 정보를 얻어 결합합니다. 예를 들어 아래와 같은 한 Time Step의 Encoder가 있다고 가정하겠습니다.
| Key | I | want | to | go | to | hospital |
| Value | I | want | to | go | to | hospital |
| Similarity | 0 | 0 | 0 | 0 | 0.15 | 0.85 |
또한 현재 상태의 쿼리를 표현하는 Decoder를 가정해보겠습니다.
| Query | 나는 | 병원에 | . | . | . | . |
'병원에'라는 단어를 기준으로 Encoder의 Key와 전부 유사도를 계산하여 linear combination을 실시합니다. 즉 to * 0.15 + hospital * 0.85와 같은 weighted sum을 실시한다는 뜻입니다. 이를 Encoder에서 나온 context vector를 구성합니다. 이 context vector는 Encoder에서의 필요한 정보를 취합된 것을 뜻합니다. 이 context vector와 Decoder의 현재 상태의 hidden state와 concat을 하여 새로운 hidden state를 구성해 부족한 정보를 채웁니다. 위의 예시는 한 time step을 표현한 것이고 이를 모든 time step을 수행합니다. LSTM을 쓸 때에는 context vector에 모든 정보를 억지로 넣는 것에 한계가 있었지만 이를 통해서 더 긴 길이의 I/O에도 대처를 할 수 있게 되었습니다.
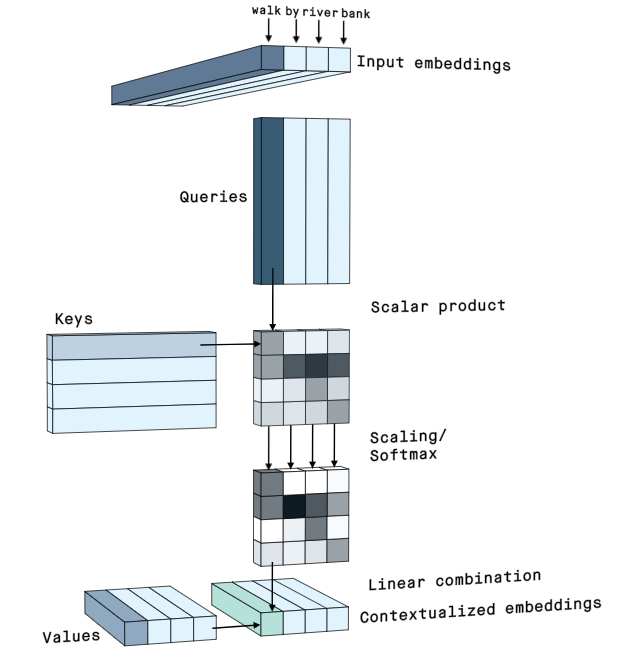
위의 그림은 Self-Attention을 정말 간단하게 잘 표현한 그림입니다. 참고로 저는 여기 아래 영상을 강력 추천 합니다.
정리하면 현재 State를 잘 반영하면서 좋은 검색 결과를 도출할 수 있는 Query를 얻는 것이 Goal이며 이것이 Attention이라고 부릅니다. 즉, 좋은 정보를 잘 얻기 위한 Query를 변환하는 방법을 배우는 과정이라고 할 수 있습니다. Attention을 더 간단하게 표현을 정성적으로 예시를 들면 다음과 같습니다. 구글이나 네이버에 "선릉역에 가장 회식하기 좋은 돼지고기 맛있는 집은 어디야?"라고 실제로 검색하지는 않습니다. 간단하게 "선릉 돼지고기 회식 맛집" 이런 식으로 검색하는 것이 좋은 결과를 얻을 수 있을 것이라 이미 사람은 학습이 되어있습니다.
이렇게 Attention에 대한 내용을 요약하는 개념으로 글을 썼지만 Jay Alammar의 attention 글을 읽는 게 제일 최고입니다. 다음 글은 Transformer로 찾아뵙겠습니다.
<Reference>
https://peltarion.com/blog/data-science/self-attention-video
Self-attention: step-by-step video | Peltarion
Step by step illustration of self-attention
peltarion.com
'AI > NLP' 카테고리의 다른 글
| Pretrained Language Model - 9. Language Model (0) | 2021.10.24 |
|---|---|
| Pretrained Language Model - 8. Transformer (0) | 2021.10.15 |
| Pretrained Language Model - 6. ELMo (0) | 2021.10.02 |
| Pretrained Language Model - 5. Word Embedding (0) | 2021.09.23 |
| Pretrained Language Model - 4. Downstream Task (0) | 2021.09.17 |
