
1. Motivation
Context Window에 단어가 동시에 나타나는 단어일수록 비슷한 단어를 가진다는 가정에서 출발을 합니다. 따라서 비슷한 단어는 비슷한 벡터 값을 가져야 합니다. 대표적인 방법으로는 Skip-gram이 있습니다.

주변 단어들을 맞추려고 하는 것이 큰 Goal이라고 할 수 있습니다. 문장의 문맥에 따라 정해지는 것이 아니고 Context Window 사이즈에 따라 Embedding의 성격이 바뀔 수 있음을 유의하셔야 합니다.
2. Basic Tactics
기본적인 개념은 상당히 AutoEncoder와 비슷합니다. y를 성공적으로 예측하기 위해 필요한 정보를 선택하며 압축을 합니다. 주변 단어를 예측하도록 하는 과정에서 적절한 단어의 Embedding을 구할 수 있습니다.
3. How do you apply transfer learning?
예를 들어서 RNN을 이용해서 Text Classification을 한다고 가정을 하겠습니다. 기존에 Word Embedding Layer(One-Hot Vector 대신 Lookup Table을 이용해 Embedding Vector로 바꾸어주는 역할, 아래 그림의 W input) → RNN Layer → Softmax Layer로 가는 흐름이였다면, Word Embedding Layer대신 Pre-trained Word Embedding Vector를 집어넣어 Transfer Learning을 진행하는 것입니다.(RNN → Softmax)
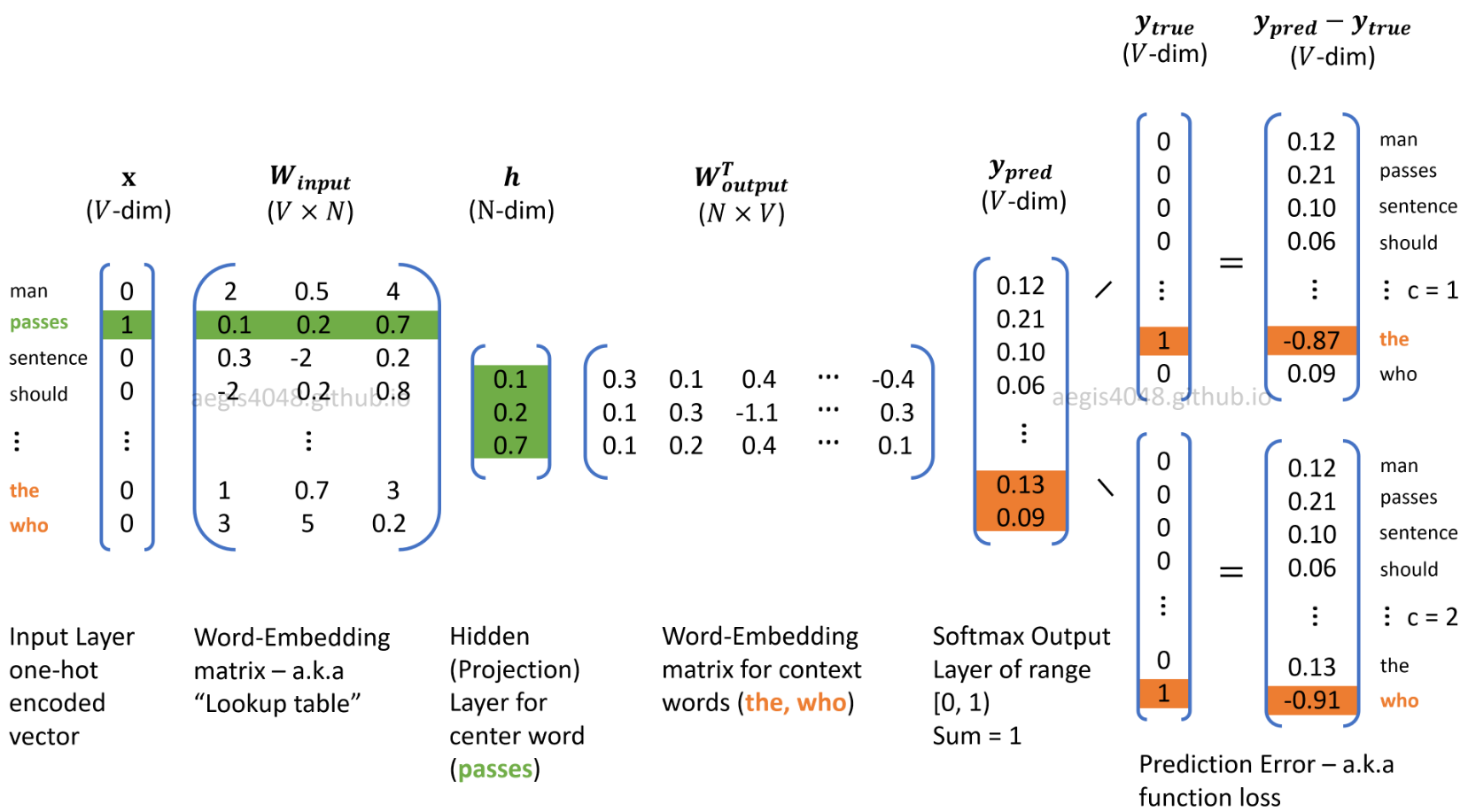
하지만 NLP에서는 오히려 Pre-trained Word Embedding Vector를 쓰는 것이 상당히 좋지 않습니다. 즉, Random initialized 된 Embedding Layer를 쓰는 것이 좋습니다. 해당 corpus나 task에 따라서 많이 상이하기 때문에 성능이 상당히 감소합니다. 차라리 Random initialized Embedding Layer를 쓰는, 즉, End-to-End 방식으로 활용하는 것이 더 좋습니다. 차라리 주식이나 상품들, 방송 시청 내역 등 sequential 한 데이터들을 모아서 Embedding 하는 것이 활용성 측면에서 좋습니다. 아래처럼 단어들을 Embedding 해서 유사도 비교하는 것도 그 예시입니다.

word2vec말고 glove, fasttext 등의 방법으로 더 좋은 품질로 Embedding을 할 수 있습니다. 하지만 이런 종류들은 전부 window를 얼마나 잡을지, epoch을 얼마나 할지 등 전부 hyperparameter들이기 때문에 좋은 품질로 Embedding하고 활용하는 것으로 끝내는 것을 권장하며 transfer learning으로 쓰기에는 실용적인 관점에서는 좋지 않다는 것을 이야기하고 싶습니다.
4. 정리
- Embedding Layer는 One-Hot Encoding된 벡터를 받아 discrete 한 것을 continuous 한 벡터로 변환하는 것이 큰 사상입니다.
- 높은 차원의 벡터를 효율적으로 계산하기 위해 고안되었습니다.
- Word2vec학습 과정에서 loss를 최소화하는데 자연스럽게 해당 task에서 비슷한 쓰임새를 갖는 단어들은 비슷한 벡터를 갖게 됩니다. 하지만 corpus나 task가 바뀌면 쓰이는 벡터가 다르기 때문에, Pre-train 된 Embedding 된 것보다 End-to-End로 Embedding Layer(lookup table)을 가져다 쓰는 것이 좋습니다.
'AI > NLP' 카테고리의 다른 글
| Pretrained Language Model - 7. Attention (0) | 2021.10.09 |
|---|---|
| Pretrained Language Model - 6. ELMo (0) | 2021.10.02 |
| Pretrained Language Model - 4. Downstream Task (0) | 2021.09.17 |
| Pretrained Language Model - 3. PLM (0) | 2021.09.14 |
| Pretrained Language Model - 2. Transfer Learning (0) | 2021.09.12 |
