다른 AutoML에 비해서 SageMaker의 autopilot은 전체 프로세스가 완료될 때까지 많은 시간이 소요됩니다.
1. 실험 데이터
Kaggle에서 mnist data를 다운로드합니다.
https://www.kaggle.com/oddrationale/mnist-in-csv
MNIST in CSV
The MNIST dataset provided in a easy-to-use CSV format
www.kaggle.com
s3을 aws에서 검색하여 새로운 이름으로 bucket을 만들고, input 폴더를 생성합니다. 그 후 해당 폴더에 mnist_train.csv파일과 mnist_test.csv를 업로드합니다. 또한 output 폴더를 만들어 둡니다.

2. autopilot experiment 실행
1) SageMaker Studio에 접속합니다.
2) Launcher 에서 New autopilot experiment를 클릭합니다.

3) experiment name 을 입력합니다.
4) S3 bucket name 과 Dataset file name을 위의 mnist dataset 경로로 지정합니다.

5) Target column 을 label로 지정합니다.

6) Output data location 을 위의 S3 bucket의 output 폴더 경로로 지정합니다.
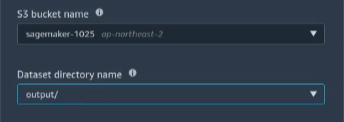
7) ML problem type 을 Multiclass classification으로 지정합니다.

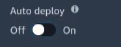
8) Auto deploy 을 off로 변경합니다. ON으로 하면 Best Model로 바로 Deploy가 됩니다.
9) Create Experiment 버튼을 클릭합니다.
과금을 원하지 않으시는 분들은 Do you want to run a complete experiment? 에서 No, run a pilot to create a notebook with candidate definitions를 체크해주시기 바랍니다. 혹은 Create Experiment 버튼을 클릭하지 않기 바랍니다.
10) 다음과 같은 화면이 나타나며, 정상적으로 autopilot experiment 가 실행되는 것을 확인합니다.

이제 2~3시간 동안 250개 정도의 model을 검증하는 과정을 전처리 → candidate definitions generated → feature engineering → model tuning 차례대로 수행합니다.
3. Autopilot 결과물 살펴보기 - 중간 진행 상황 살펴보기
autopilot experiment가 완료되면 함께 autopilot의 결과물인 Generated Notebook을 살펴봅니다.
약 20분 정도 지나면, pre-processing 및 candidate definition generated 스텝이 완료되고 우측 상단에 Open candidate generation notebook, Open data exploration notebook 버튼이 생성됩니다.

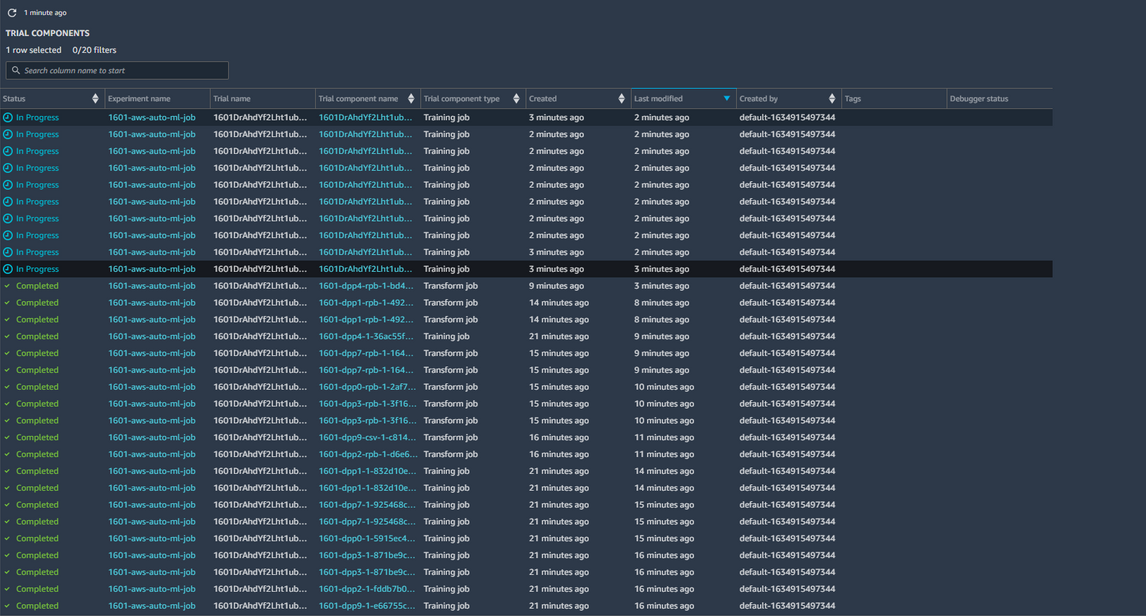
진행 프로세스에서 생성된, 데이터는 output 경로로 입력한 s3 버킷에 저장합니다. Model Tuning 단계에 들어서면, 본격적으로 모든 Model 에 대해 HPO 과정을 거치는데 각 모델에 대한 진행 상황은 다음과 같이 확인 가능합니다.
experiments and trials 클릭하고, describe automl job을 클릭하면

각 trial의 진행상황이 확인이 가능합니다.
4. Autopilot 결과물 살펴보기 - Data Exploration Notebook
생성된 EDA 노트북 샘플은 다음처럼 나타납니다.

전체적인 흐름은 input data 를 train/valid dataset으로 split을 했고, Data의 size는 어떻게 되고, 어떤 칼럼을 target으로 사용했으며, multiclass 분류 문제를 풀었고... 등등에 대한 내용이 있습니다.
1) Dataset 샘플 보여주기
흔히 첫 단계로 Dataframe 의 head를 보여주는 것과 동일합니다.
2) Dataset 에 대한 기본적인 통계 분석으로는 다음과 같은 것을 제공합니다.
- column 별 data type
- column 별 missing value의 개수
- missing value 가 너무 많으면 진짜 믿을 수 있는 데이터가 맞는지 확인해보라는 Suggestion comment 도 달립니다.
- column 별 unique value 의 개수
- column 별 기본적인 statistics
5. Autopilot 결과물 살펴보기 - Candidate Definition Notebook
아래와 같은 샘플이 나타납니다.

어떤 ML task 이고, 어떤 metric을 maximize 하는 AutoML experiment 였는지 등을 설명합니다.
1) SageMaker Jupyter notebook 에서 AutoML의 결과물을 어떻게 사용해볼 수 있는지에 대한 Setup 방법 설명합니다.
2) Generated Candidate Pipelines (Feature selection + Model + HP) 에는 어떤 조합들이 있었는지, 어떤 타입의 리소스를 사용했는지에 대한 설명합니다.
3) 각 Candidate Pipeline을어떻게 재현해볼 수 있는지에 대한 설명합니다.
4) Best Model 을 어떻게 SageMaker Endpoint로Deploy 할 수 있는지에 대한 설명합니다.
다음 글에서는 GCP 관련 내용으로 찾아뵙겠습니다.
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
* 본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
 |
 |

'AI > MLOps' 카테고리의 다른 글
| [패스트캠퍼스 챌린지 48일차] GCP - Feast Feature Store (2) (0) | 2022.03.12 |
|---|---|
| [패스트캠퍼스 챌린지 47일차] GCP - Feast Feature Store (1) (0) | 2022.03.11 |
| [패스트캠퍼스 챌린지 45일차] Amazon SageMaker 계정 생성 & Amazon SageMaker Autopilot (0) | 2022.03.09 |
| [패스트캠퍼스 챌린지 44일차] Python 기반 Jenkins CI Pipeline Build (0) | 2022.03.08 |
| [패스트캠퍼스 챌린지 43일차] Jenkins CI Pipeline Build (0) | 2022.03.07 |
