두 번째 리뷰 Paper는 "Buy Tesla, Sell Ford: Assessing Implicit Stock Market Preference in Pre-trained Language Models"입니다. 제목을 간단하게 번역하면 "(테슬라 사고 포드 파세요~) 사전 훈련된 언어 모델(PLM)에서 내재된 언어 모델 주식 선호도 평가"라고 해석이 가능합니다. 언어 모델이 발달함에 따라서 여러 도메인에 많이 보급이 되었고, 이전에 소개한 논문리뷰 "FinBERT" 언어 모델 또한 그렇습니다. 여기 논문에서는 언어 모델이 전반적으로 주식 시장에 선호하는 편향을 가지고 있으며, 섹터들끼리 또는 섹터 내에서 선호도 차이가 상당하다는 것을 발견했다는 논문입니다. 이러한 문제에 대한 인식을 가져봐야 한다는 논문입니다.
Masked Token 예측하기
이전 글에 소개했던 Pretrained Language Model인 FinBERT 또한 BERT 모델의 알고리즘은 동일합니다. (큰 차이점은 Pretrain 시 2020년 어닝 콜과 Analyst의 분석 리포트들의 내용이 데이터로 활용되었습니다.) 편리하게 자연어 관련 Pretrain 모델을 활용할 수 있는 Huggingface에서 Hosted Inference API를 활용하면 따로 PLM을 다운로드하지 않고 간단하게 사용이 가능합니다.
https://huggingface.co/yiyanghkust/finbert-pretrain
yiyanghkust/finbert-pretrain · Hugging Face
FinBERT is a BERT model pre-trained on financial communication text. The purpose is to enhance financial NLP research and practice. It is trained on the following three financial communication corpus. The total corpora size is 4.9B tokens. Corporate Report
huggingface.co
여기 위에 접속 후 다음과 같은 2개의 문장을 넣어서 Inference 하여 비교해봅니다.
tesla stock share is going to [MASK].
ford stock share is going to [MASK].
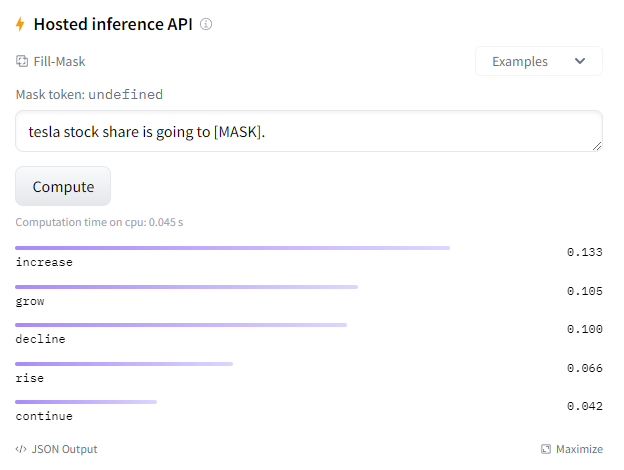

Mask 토큰에 대해서 들어갈 수 있는 단어가 종목에 따라 차이가 있음을 확인할 수 있습니다. 하지만 일반적인 BERT는 어떤 결과를 가져오는지 확인해보겠습니다.
https://huggingface.co/bert-base-uncased
bert-base-uncased · Hugging Face
BERT base model (uncased) Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this paper and first released in this repository. This model is uncased: it does not make a difference between english and
huggingface.co
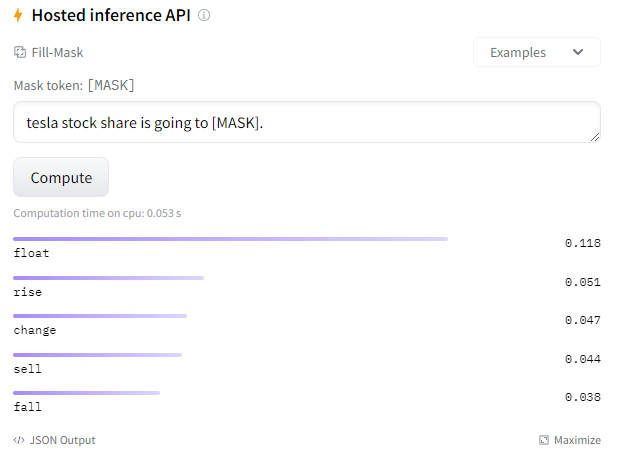
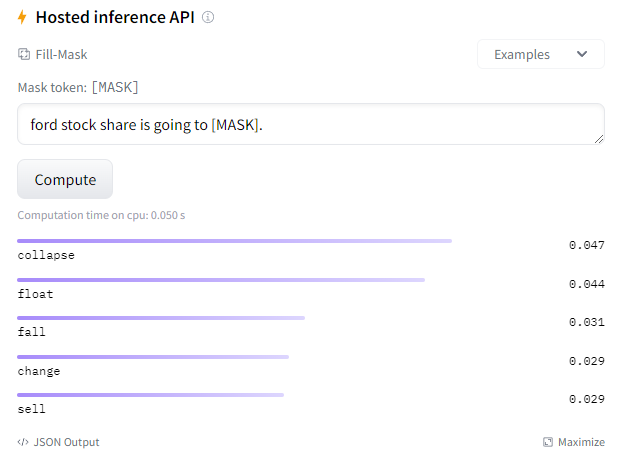
두 모델이 Tesla를 선호를 하고 Ford를 상대적으로 부정적으로 보고 있는 편향을 보여줍니다. 더욱 놀라운 것은 앞뒤에 아무런 Semantic 한 요소가 없는데 이런 식으로 Mask Token을 채운다는 점입니다. 즉, bias 한 요소를 학습을 했다는 것을 알 수 있고, 금융 자연어 분야에서 이러한 Specific 한 BERT 모델마저도 편향에 취약하기에 무작정 활용하는 것은 위험하다는 것을 인지할 필요가 있습니다.
실험 1 : Implicit preferences in the market
위의 예시로는 부족하다고 누구나 느끼실 수 있습니다. 이번에는 Market에서 내재된 선호도 평가를 실험하는 내용입니다.
실험 데이터 러셀 3000에 편성된 종목 티커가 반영되어있는 아래와 같은 데이터를 준비합니다. C Column에서 GICS(Global Industry Classification Standard)는 11개의 부문(Sector), 24개의 산업 그룹 등이 반영된 코드라고 생각하시면 됩니다.

위에 있는 티커가 포함된 문장(1)과 BERT와 FinBERT가 매수 및 매도 의견의 문장(2)을 낼 확률을 비교합니다. (1-cosine)


[Ticker] is a stock. (1)
we should buy(or sell) the stock. (2)
그 후 아래 확률 값의 결과를 BoxPlot으로 그리면 아래와 같습니다. Boxplot y축은 어떤 티커들이 있을 때 매수 의견을 낼 확률입니다(0.5 아래는 매도). 확실히 FinBERT에서 매수 의견을 상당히 많이 내는 것을 알 수 있습니다. 참고로 Russell 3000 종목은 2020년 하반기에 엄청난 Bullish 한 장이였습니다.

실험 2 : Implicit preferences between industries
또 다른 실험은 티커 별로선호하는 확률들을 총 GICS 11개의 섹터에 대해 sum을 했을 때, GICS Sector 별로 어떠한 선호도를 가지고 있는지 확인하는 내용입니다.(자세한 설계 방법은 논문 참고)

Table 3에서은 univariate regression의 결과로 회귀 계수(Beta)의 부호 값들이 들어있습니다. 양수라면 선호한다고 해석을 하고, 음수라면 선호하지 않는다고 이해를 하시면 됩니다. 결과를 보면 BERT와 FinBERT는 Finance에서는 매수한다는 것을 피하는 것을 알 수 있지만, BERT는 Materials, Industrials 섹터의 주식들을 선호하고, FinBERT는 Utilites나 Information Technology 섹터를 선호하는 것을 보여줍니다. 또한 BERT는 특정 섹터만을 선호하고 FinBERT는 대부분의 섹터를 선호하는 것을 알 수 있습니다.
마무리
아무리 많은 데이터를 부은다고 한들, 결국 학습하였던 데이터가 Bias를 가지고 있다면 Bias를 학습하는 것이나 다름이 없습니다. BERT는 언어 모델이고 언어의 큰 형태는 크게 변하지 않지만, 활용하는 데이터가 시계열 적으로 편향이 강하다면 이러한 기술을 쓸 때 유의하는 것이 좋다는 생각이 들었습니다. 레시피(Algorithm)와 요리 도구(GPU)가 좋아도, 요리 재료(Data)가 좋아야 맛있어지는 것이기 때문에, 데이터의 중요성을 한번 더 깨닫게 되는 논문이었습니다. 또한 특정 도메인에 대해 BERT는 정말 좋은 성능을 발휘하지만 유동적으로 계속 살아 움직이는 금융시장에서는 조금 유의하는 것이 좋다는 점입니다. 다른 관점에서 이번 논문을 읽고 드는 생각은, 퀀트에서 보통 개별 종목 단위의 전략들이 상당히 많은데 오히려 섹터나 테마별로 다루는 곳에 접목하는 것도 괜찮겠다는 생각이 들었습니다. 다음에도 재미있는 내용을 발견하면 조금씩 리뷰해나가보겠습니다.
+) 논문 리뷰 시 한 줄씩 읽지 않고 눈에 들어오는 부분만 읽었기 때문에 틀린 점이 있을 수 있습니다. 아래 Reference의 실험 코드와 논문을 곁들여서 같이 보는 것을 추천합니다.
Reference
* 해당 논문은 아래에 있습니다.
https://aclanthology.org/2022.acl-short.12/
* 해당 논문에서 실험 관련 코드는 아래에 있습니다.
https://github.com/MattioCh/Buy-Tesla-Sell-Ford
GitHub - MattioCh/Buy-Tesla-Sell-Ford
Contribute to MattioCh/Buy-Tesla-Sell-Ford development by creating an account on GitHub.
github.com
* 이전 FinBERT 관련 글
[퀀트 논문 간단 리뷰] FinBERT - A Large Language Model for Extracting Information from Financial Text
퀀트 전략 관련하여 간접적으로 도움이 될 만한 논문들을 여유가 될 때마다 리뷰하고자 합니다. 하지만 그냥 일반적으로 유명하다고 알려진 논문보다는 필자가 직무는 AI 쪽에 조금 더 가깝고
hotorch.tistory.com
'Investment - Stock & Crypto > Quant Strategy' 카테고리의 다른 글
| [퀀트 논문 간단 리뷰] FinBERT - A Large Language Model for Extracting Information from Financial Text (0) | 2022.11.13 |
|---|---|
| Mean Reversion(역추세 매매) - RSI 2 (1) (0) | 2022.03.27 |
| 비트코인 마켓타이밍 분석 (3) (2) | 2021.11.14 |
| 비트코인 마켓타이밍 분석 (2) (5) | 2021.11.06 |
| 비트코인 마켓타이밍 분석 (1) (2) | 2021.10.25 |
