
1. Motivations
처음에 전이학습이 나온 분야는 비전입니다. 데이터가 다르더라도 이미지를 활용한 공통된 Feature들이 존재할 것이라고 접근합니다.

꽃은 잎 모양, 길이가 비슷하나 조금씩 다 차이가 있습니다. 최소한의 공통적인 Feature를 활용하겠다는 사상에서 출발을 합니다.
2. Common Feature in NLP
NLP에서는 공통적인 Feature들을 어떻게 뽑을 수 있을까요?
<쉬운 표현>
I love to go to market.
I would like to go home.
You have to go to school.
....
Corpus에 위와 같은 쉬운 표현들을 보면 semantic, syntactic 한 요소들이 사람이 보기에 쉽게 보일 수 있습니다.
<어려운 표현>
I wish to precarious A around.
위와 같이 precarious와 같은 단어가 Corpus에 상당히 적게 있을 가능성이 높습니다. 하지만 위의 쉽고 typical 한 표현들을 학습해 semantic, syntactic 한 부분을 유추해 나갈 수 있습니다.
3. 정의
내가 어떤 특정 문제를 푸는데 있어 연관되면서 유사한 다른 문제에 학습한 저장된 지식을 활용한다고 생각하시면 됩니다.

4. 방법
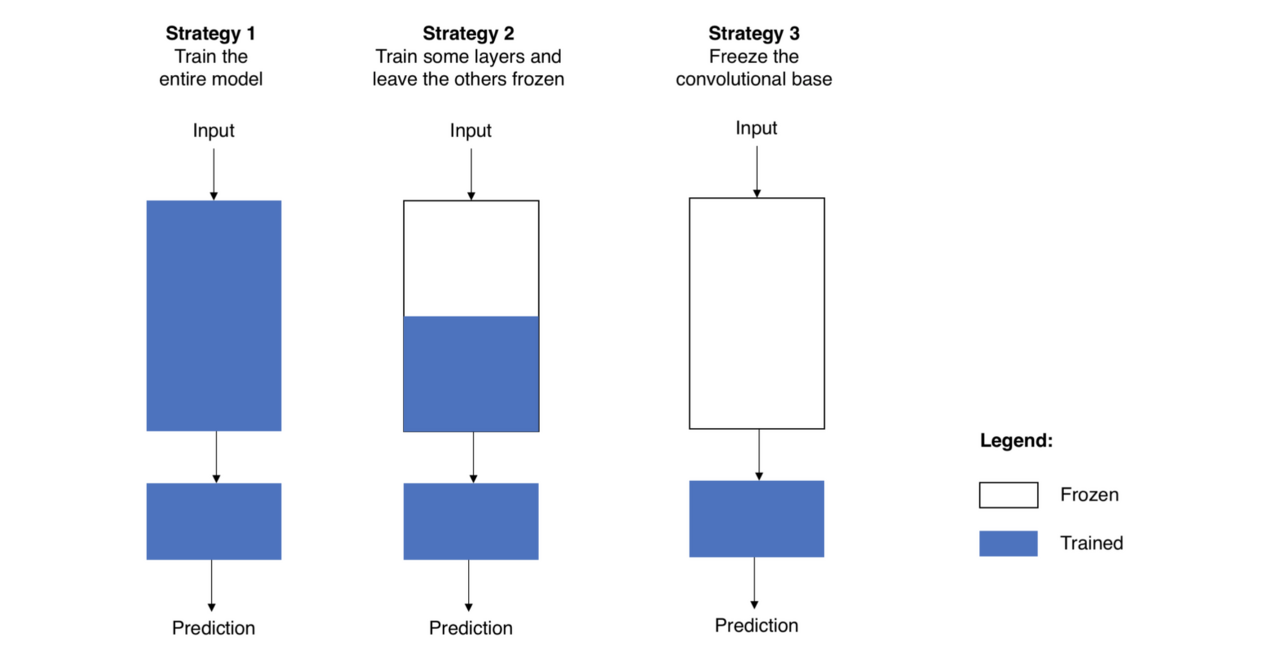
방법은 다양합니다. 위의 큰 사각형이 Big Dataset을 이용한 모델(사전학습 용)이라고 생각하고, 아래 작은 사각형을 나의 Target Dataset을 활용한 모델(Fine tuning)이라고 생각하겠습니다.
첫째는 전체 weights를 활용하는 것입니다. 전부 새로 학습시키는 방법이라고 생각하시면 됩니다. 두 번째는 본인 상황에 맞게 파라미터들을 활용하는 것입니다. 데이터셋이 작고, 파라미터가 많아 무거운 경우에는 과최적화 위험이 있기에 가볍게(계층을 적게 쌓고, learning rate를 크게)할 수 있고, 반대인 경우에는 조금 더 많이 학습시켜 본인 상황에 맞게 적합한 모델로 개발할 수 있습니다. 세 번째는 Target Dataset의 모델만 재학습 시키고 특징 추출한 부분은 그대로 활용하는 것입니다.
5. 정리
대부분의 데이터들은 공유할 Feature들이 있다는 것입니다. 이미지같은 경우에는 경계선이나 모양, 길이 등이 있고 텍스트는 문법적이나 의미론적인 부분을 뜻하는 것입니다. 상황과 전략에 맞게 신경망을 Random seed에서 학습하는 것보다 다른 비슷하고 큰 데이터셋을 통해 학습한 뒤 학습하는 것이 Transfer Learning이 방법입니다. 그래서 ResNet이나 BERT와 같이 미리 훈련한 딥러닝 모델을 활용해서 나의 문제에 Fine Tuning을 하는 것이 Trend라고 할 수 있습니다.
Reference
'AI > NLP' 카테고리의 다른 글
| Pretrained Language Model - 4. Downstream Task (0) | 2021.09.17 |
|---|---|
| Pretrained Language Model - 3. PLM (0) | 2021.09.14 |
| Pretrained Language Model - 1. Self-supervised Learning (0) | 2021.09.12 |
| Pretrained Language Model - 0. Intro (0) | 2021.09.12 |
| 자연어 강좌 추천(2020) (0) | 2020.07.12 |
