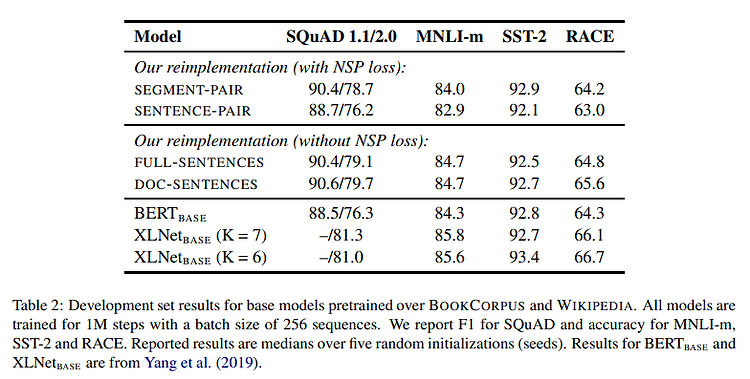
BERT를 Robust 하게 최적화하는 방법에 대해서 논의해보려고 합니다. 정말 사랑받는 모델인 BERT이지만, 학습하는데 많은 시간과 돈이 들었는데, 정말 hyperparameter가 잘 최적화가 되었는가에 대한 의문으로부터 출발합니다. 1. RoBERTa vs BERT - BERT보다 10배 이상 더 많은 데이터를 더 오래오래 학습시켰습니다. - 안그래도 말 많은 NSP task, 불필요하다고 판단하여 제거를 하였습니다. - 모든 샘플들에 대해 Max sequence length를 512로 맞춰서 구성하였습니다. 길게 길게 입력을 주었습니다. - 기존 BERT에서는 Pretrain 데이터에 대해서 masking을 정적으로 해놓고 들어가는데(한번 빈칸 뚫고 그냥 쭈욱 진행했다는 점), RoBERTa는 ..

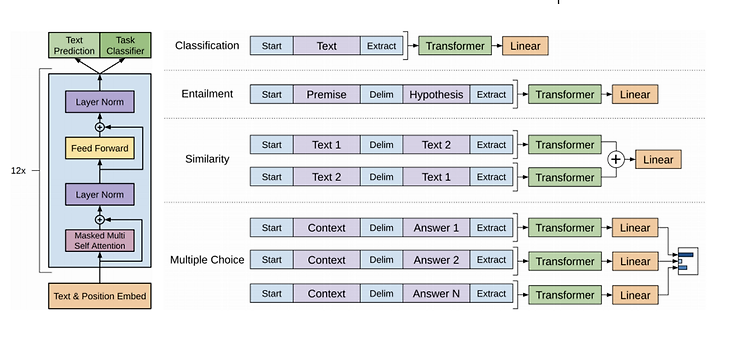
PLM계열의 Auto-Encoder 계열, 가장 많이 쓰이고 활용되고 있는 BERT 차례입니다. 이전에 글 쓴 GPT 계열은 단방향(Uni-directional) 언어 모델이기 때문에, 문장 앞까지만 보고 추측하는 것이기 때문에 문장 전체에 대한 이해가 부족합니다. 마치 한국어는 끝까지 들어봐야 한다라는 말이 있듯이 BERT 계열은 Bi-directional 언어 모델이기 때문에 Fine-Tuning 단계에서 꽤 많은 성능을 올릴 수 있습니다. 0. BERT와 이전 모델의 차이점 - BERT : Performance가 검증된 트랜스포머 블록을 사용 + 모델의 속성이 양방향을 지향하는 점에 있습니다. - GPT는 왼쪽에서 오른쪽으로 한 방향(uni-direction)으로만 보는 아키텍처(언어모델) 입니다...
이전 시간에는 Language Model과 Tokenization(BPE Algorithm)에 대해서 다루었습니다. 본격적으로 PLM을 하나씩 언급해볼 예정입니다. 먼저 PLM의 유형들이 어떤 것이 있는지 알아보면 다음과 같습니다. 1. PLM의 유형 - Autoregressive models : Open AI의 GPT와 같이 NLG Task에 강점이 있는 모델을 뜻하며, Transformer의 Decoder만을 이용해 LM을 구성합니다. - Autoencoder models : 가장 많이 활용되며, 구글의 BERT와 같이 NLU Task(CLS, NER 등)에 강점이 있는 모델이며, Transformer의 Encoder를 통해 LM을 구성합니다. Bi-directional LM이 구현 가능하며 MLM,..
NLP에서 데이터를 모델에 바로 집어넣는 것이 아닌 tokenization을 반드시 거쳐주어야 합니다. 문장 속 단어들은 여러 단어가 결합되어 나타나기 때문에, 반드시 이 것을 나누어서 컴퓨터가 더 이해하기 쉽게 작업을 거쳐주어야 합니다. 기호(괄호, 따옴표, 마침표 등)을 나누는 것은 기본이고 NLP에서 난이도가 최상위권인 한국어 같은 경우에는, Mecab과 같은 형태소 분석기를 활용하여 어미와 접사를 분리를 해주는 것이 일반적인 것으로 알려져 있습니다. 왜 이 작업이 필수인 이유는 가장 NLP 하면서 스트레스를 많이 받게 되는 OoV(Out of Vocabulary) 문제이기 때문입니다. 1. OoV(Out of Vocabulary) - 여러 단어가 결합되어 있을 때, 이를 나누지 않으면 Corpus..
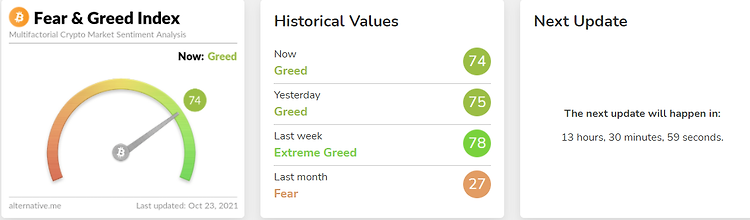
1. Intro & Background 최근에 비트코인 상승세가 강합니다. 그 이유는 여러 가지 있겠지만 최근 한 달 강하게 견인하고 있는 요소는 비트코인 선물 ETF 승인이 한 몫한 것 같습니다. 마찬가지로 현재 글 작성 시간 기준 Fear & Greed Index도 Greed 단계임을 알 수 있습니다. 추석 때부터 코인 관련 책을 읽었고 이더리움도 아기자기하게 조금 들어갔습니다. 최근에 저는 Coin 자동매매를 공부 및 구축을 따로 하고 있습니다. (그 계기는 여기 글에 서술을 했습니다.) 제일 먼저 만만하게 입문하기 좋아보이는 책으로는 "가상화폐 투자 마법 공식" 이라는 책입니다. 2014년 2월부터 2018년 까지 백테스팅된 결과가 있기 때문에 최근 기간까지 반영은 안 되어 있지만 입문하기는 좋아..

저번 시간 Transformer에 대해 다루었습니다. 조금 더 기초로 돌아가보는 시간 가지겠습니다. NLP에서 가장 근간이 되는 것은 단연 Language Model 입니다. 매우 간단하게 설명하면 토익 Part 5와 같다고 생각하시면 되는데 다음의 빈칸에 알맞은 단어를 고르면 됩니다. 우리 인간은 상당히 많은 말을 일상에서 주고받기 때문에 자연스럽게 단어와 단어사이에 무슨 단어가 들어가야할 지, 어떤 단어가 들어가야 좋은지 학습이 매우 잘 되어 있습니다. 빈칸에 들어갈 확률이 어느게 높은지 잘 학습이 되어있다는 뜻입니다. 언어모델은 위처럼 쉽게 설명하면 그렇지만 수학적으로는 "문장의 확률 분포"를 나타낸 모델이라고 정의할 수 있습니다. 이전 단어들이 주어졌을 때 다음 단어의 확률을 예측하거나, 문장의 ..

저번 시간에는 ETF를 바탕으로 간단하게 전략들을 구성하는 예시들을 보여드렸습니다. 백테스팅은 정해진 전략을 기반으로 과거에 대입하여 매수, 매도하는 시뮬레이션 행위입니다. 이 블로그 자산배분 시리즈에서 중반에 나오는 데이터 수집과 최적화 부분은 Python도 할 줄 아는 사람이 따라 할 수 있는 시리즈라 피곤하기도 합니다. 하지만 요새는 백테스팅도 좋은 Tool이 많습니다. 저번 글에 소개한 High level 툴인 Portfolio Visualizer도 유명하며, 해외에는 alpha architect, quantpedia, quantconnect가 있으며 국내에는 IntelliQuant, backtest.kr, Genport, 퀀트킹 등이 있는 것으로 알고 있습니다. 우리가 결국엔 의지하며 기댈 곳은..
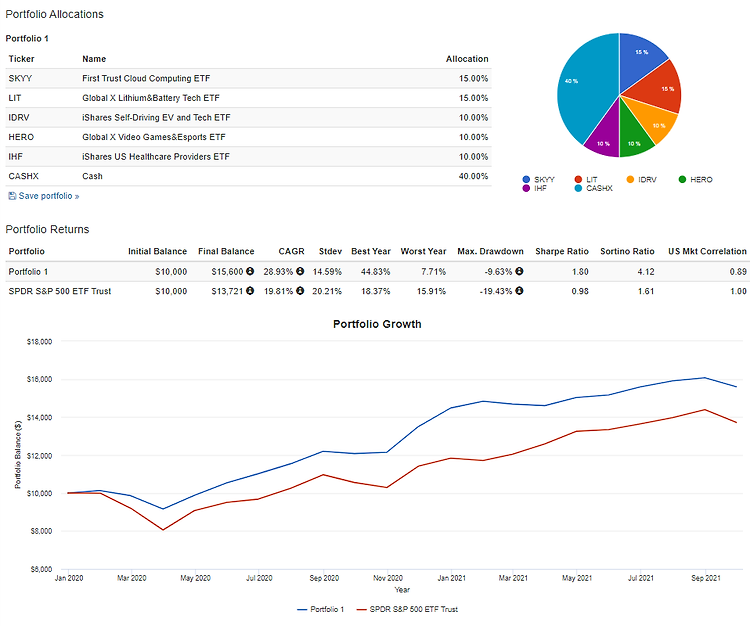
저번 시간에는 Portfolio Visualizer를 이용하여 개별종목만으로 포트폴리오를 구상할 수 있는 것을 알려드렸습니다. 종목이 10개로 되어있어서 상당히 입력하는 데 조금 불편하신 분들도 있었을 겁니다. 물론 ETF만으로도 심플하게 구성을 할 수 있습니다. 간단하게 4가지 정도 컨셉의 전략을 구성해서 소개해보겠습니다. 각 티커들은 각자 리서치하시면서 어떤 것인지 확인하시는 것도 추천드립니다. 첫 번째는 방어형 컨셉을 지닌 포트폴리오 전략입니다. 참고로 RPAR이라는 올웨더 포트폴리오 ETF가 2019년에 상장된 신생 ETF이기 때문에 기간이 짧은 것이 단점입니다. 또한 이 포트폴리오는 MDD가 상당히 작지만 벤치마크인 SPY를 이기진 못합니다. 그래도 리스크 대비 수익은 좋은 편입니다. 아마 제가..
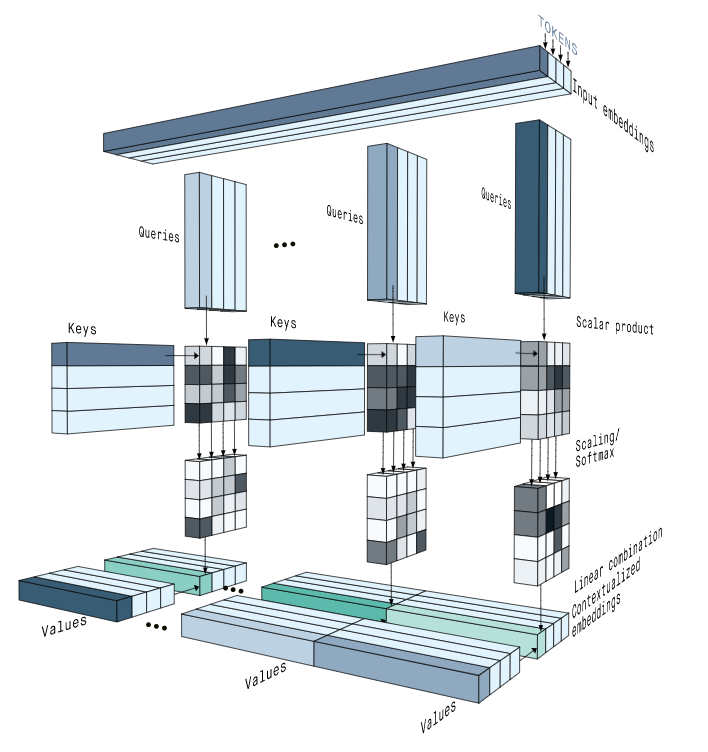
저번 시간에 Attention에 대해 다루었습니다. 솔직히 제일 처음에 Transformer를 공부할 때 이해가 되질 않았던 기억이 있습니다. 또한 논문 'Attention is all you need'도 초보자가 읽기에 너무 힘들었던 기억이 납니다. 여러 글(Jay alammar의 블로그와 ratsgo님의 블로그)과 유튜브 영상 등을 보고 구현을 하다 보니 이해가 되었고 이를 간단히 정리하고자 합니다. Transformer는 Attention 연산을 통해 정보의 encoding과 decoding을 해결합니다. RNN은 구조상 순서의 정보가 반영이 되어있지만 Attention은 그렇지 않아 순서의 사상을 반영해야하기 때문에 Positional Encoding을 사용하여 반영합니다. Positional E..
워낙 두분이 다루시는 내용들이 방대하다보니 양이 상당한 것 같습니다! 108개 챕터! https://cafe.naver.com/invest79/12999 강환국 & systrader79 퀀트 자료 collection vol.2.pdf 전자책 공유합니다 (108개 chapter, 489 페이지) 대한민국 모임의 시작, 네이버 카페 cafe.naver.com 공부할 것이 상당히 많습니다! 많은 분들이 성투하면 좋겠습니다!