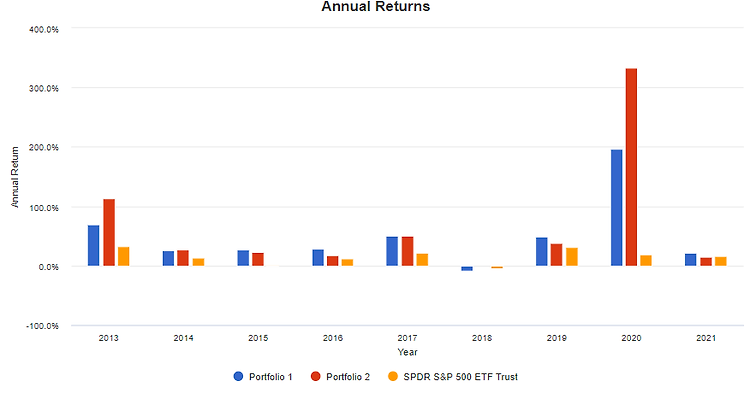
지난 글에서는 종목들의 비중을 최적화한 이야기를 했었습니다. 하지만 Python 코드를 이용해서 종목 비중을 최적화하기엔 누군가에게는 어려울 수 있기 때문에 간단한 High-Level 툴을 소개하고자 합니다. Portfolio Visualizer라는 Tool은 간단한 로직으로 빠르게 백테스트할 수 있는 좋은 서비스입니다. 머릿속에 아이디어가 있을 때 저도 간단하게 돌려보기도 합니다. 내가 생각한 아이디어가 과거에서는 어느 정도 수익을 보장하고 리밸런싱을 어떻게 해야 하는지 전략을 세우는 데 있어서 도움을 줍니다. 사용법을 퀵하게 알아보겠습니다. 초기화면은 다음과 같습니다. 왼쪽에 Backtest Portfolio를 누릅니다. 테스트 기간과 초기 시드 등등에 여러 가지 내용을 입력할 수 있습니다. 항목을 ..
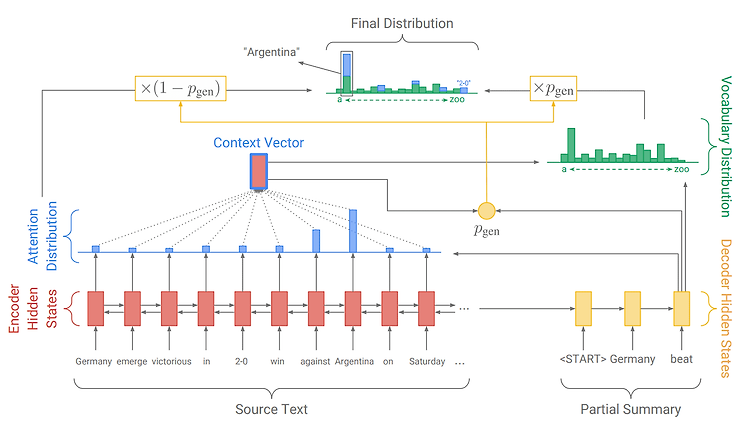
Natural Language Generation은 auto-regressive task로 접근합니다. 즉, Language Model은 주어진 단어들을 바탕으로 다음 단어를 예측하는 형태이고 가장 기본이 되는 것이 Sequence to Sequence(seq2seq) 입니다. Sequence to Sequence는 3개의 서브 모듈 Encoder, Decoder, Generator로 구성이 되어있습니다. Encoder는 문장 하나를 context vector로 압축하는 역할, Decoder는 context vector를 conditional 하게 받는 조건부 LM입니다. Generator는 Decoder의 매 Time step별 hidden state를 softmax를 통해 multinoulli dis..

안녕하세요. 이전에 주식 유튜브 추천의 글을 공유한 적이 있었습니다. https://hotorch.tistory.com/43 (내 수익에 큰 기여를 한)주식 유튜버 추천 저도 주식을 시작한 지 곧 1년이 다되어가지만, 주변에 많은 사람들이 주식을 시작하는데 무엇부터 해야 할지 모르겠다고 많은 질문을 받습니다. 저도 체계적으로 배운 것은 아니지만, 여가 시 hotorch.tistory.com 위의 글에서 4번째로 소개한 할투 유튜브 강환국 선생님(제 마음속의 아이돌)의 유튜브를 정말 즐겨보는데요. 그리고 제가 주식 책 읽은 것 중에는 항상 Systrader79님이 있습니다. 이 두 분의 퀀트 자료를 모은 것을 공유합니다! 아직은 시드가 크지 않기 때문에 자산배분은 천천히 공부할 생각이지만 엄청난 양질의 자..
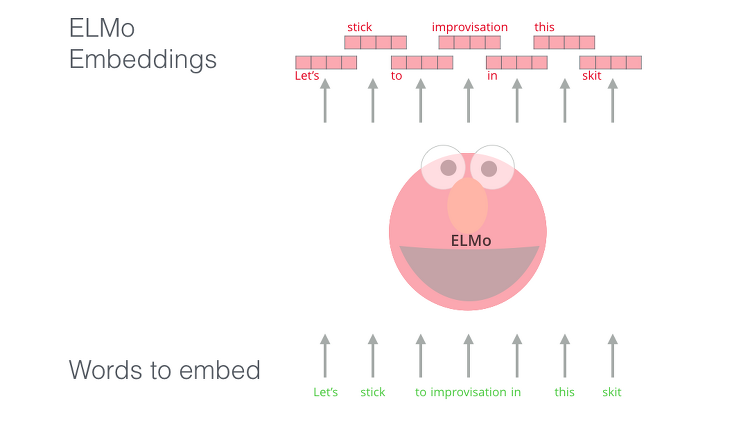
이전 글 Word Embedding에서 동시에 출현하는 단어들이 비슷한 Embedding을 갖도록 학습이 되는 것이 목표라고 이야기를 했었습니다. 하지만 Pre-trained 된 Embedding 벡터를 활용하여 썼을 때 end-to-end 방식보다 성능이 떨어진다고 언급했었습니다. Skip-gram과 같은 Word Embedding 방식들은 단어들이 바뀌다고 해서 문장의 Word Embedding값들이 바뀌는 것이 아닙니다. 해당 Corpus 내의 데이터 셋 내에서는 Global 하게 고정된 것입니다. 정말 간단하게 이야기하면 '배'라는 단어는 3가지 뜻을 가질 수 있습니다. 과일의 배, 바다에 떠다니는 배, 사람 신체의 배 이렇게 동음이의어처럼 이런 경우들은 전부 고정된 임베딩 벡터라는 것이 큰 문제..
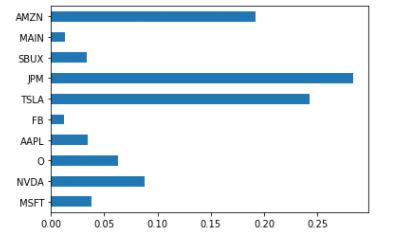
저번 글에서 동일 비중으로 우리가 들어본 듯한 회사들을 구성하여 기술주, 은행주, 배당주 10개만 적당히 굴려도 괜찮은 퍼포먼스(연평균 단순 기대수익률 33%, 리스크 21%, Sharpe Ratio는 1.56)가 나오는 결과를 얻었습니다. 이번 시간에는 조금 더 많은 시뮬레이션을 통해 비중을 최적화시켜 수익률을 개선시키고 리스크를 줄이는 방법에 대해 이야기해보겠습니다. 저번 글의 코드가 이어지니 참고하시면 좋겠습니다. daily_ret = df.pct_change() # 2013년 1월 1일 ~ 2021년 8월 27일까지 10종목 수정 종가데이터의 일별주가상승률 annual_ret = daily_ret.mean() * 252 # 연평균 주가상승률 daily_cov = daily_ret.cov() # 일..

이전 글에 이어서 후기를 이어나가겠습니다. 이전 글은 데이터 모양새와 대회 개요에 대한 내용이었다면, 이번 글은 문제를 푸는 방식에 대해 서술합니다. 6. 문제를 푼 방식 6-1. 전처리 및 결측 처리 - 결측은 공백을 채우거나, 전부 다 채워져 있는 '과제명' 열을 채우거나 했습니다. ML 쪽과 PLM 쪽은 조금씩 다르지만 대체적으로 전처리는 숫자들은 대체하고, 영문은 소문자로 대체, 특수문자와 띄어쓰기 등은 공백으로 처리하는 수준이었습니다. 기술적인 문제를 다 풀고 한계점을 찍었을 때 10에 9는 데이터 문제였던 경험이 있는데, 여기 단계가 성능을 엎을 만한 제일 중요한 단계였을 수 있습니다. 상위권이 쓰는 방법은 거의다 비슷하기 때문에, 과거에도 이런 부분을 조정을 했을 때 등수가 막 치고 올라가면..

1. Motivation Context Window에 단어가 동시에 나타나는 단어일수록 비슷한 단어를 가진다는 가정에서 출발을 합니다. 따라서 비슷한 단어는 비슷한 벡터 값을 가져야 합니다. 대표적인 방법으로는 Skip-gram이 있습니다. 주변 단어들을 맞추려고 하는 것이 큰 Goal이라고 할 수 있습니다. 문장의 문맥에 따라 정해지는 것이 아니고 Context Window 사이즈에 따라 Embedding의 성격이 바뀔 수 있음을 유의하셔야 합니다. 2. Basic Tactics 기본적인 개념은 상당히 AutoEncoder와 비슷합니다. y를 성공적으로 예측하기 위해 필요한 정보를 선택하며 압축을 합니다. 주변 단어를 예측하도록 하는 과정에서 적절한 단어의 Embedding을 구할 수 있습니다. 3. ..
Downstream Task는 간단히 말해 구체적으로 내가 풀고 싶은 문제들을 말합니다. 스택오버플로우에서 퍼온 영문 의미는 아래와 같습니다. Downstream tasks is what the field calls those supervised-learning tasks that utilize a pre-trained model or component. 1. 전형적인 NLP에서의 I/O 빨간색 부분이 Input, 파란색 부분이 Output이라고 할 때, NLP에서 자주 쓰이는 유형은 3가지로 정할 수 있습니다. 1) Many to One : 텍스트 분류 Task가 여기에 해당합니다. 긍정/부정이나 multiclass 등등 제일 많이 활용하는 분야가 분류 Task라고 생각합니다. 2) One to Man..

대회 결과는 이전 글을 참고하시길 바랍니다. https://hotorch.tistory.com/59 1. 대회 간단 소개 및 도메인 간단히 이야기하면 국가 연구개발과제를 '기후기술분류체계'에 맞추어 예측하는 모델을 개발하는 것입니다. 즉, 방대한 R&D 문헌들 중 기후 기술 연구 내용을 분류하는 것입니다. 저도 처음 들었을 때 기술 문서 분류면 쉬울 것 같다고 생각했지만, 살펴보니 기후 기술들을 더 자세히 분류하는 데이터였습니다. 그리고 정말 처음 보는 내용이 많았고 기후 기술이 상당히 광범위함을 알았습니다. 2. 데이터 간단 소개 - Multiple Text 보통 다들 NLP를 공부 시작하게 되면 IMDB, NSMC와 같은 single text인 경우에 대해서만 다루었습니다. 조금 더 발전하면 sing..
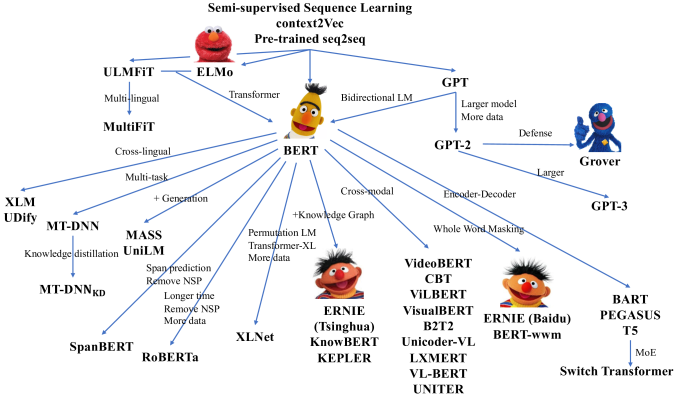
1. Review 지난 시간에는 Self-supervised Learning을 통해서 좋은 weight parameter를 얻고, Transfer Learning을 통해 본인이 가지고 있는 한정된 데이터셋과 할당된 task에 활용해 더 좋은 성능을 얻는 것이 목표였습니다. 2. transformer 트랜스포머는 추후에 조금 더 자세히 기술할 생각입니다. 워낙 블로그에 좋은 글이 많기 때문입니다. 2017년 구글에서 'Attention is all you need' 논문에서 아키텍처를 제안하며 rnn 기반의 seq to seq를 대체하였습니다. 즉, 어텐션만을 활용하여 더 뛰어난 아키텍처를 구성하였고, 이것이 자연스럽게 유행하면서 이를 PLM에 활용하여 유행하게 되었습니다. 이제는 NLP뿐만 아닌 다른 분..